


对ChatGPT的解构和复现,率先跑出来的会是谁?
当下大模型赛道的现状:一边是创业公司基于开源大模型速成,一边是大厂在各种内卷大模型参数。
据机构不完全统计,目前中国10亿参数规模以上的大模型已发布79个。在大参数内卷的过程中,市场开始出现另一种声音“不具备发展方向的参数提升是没有意义的”。
为此,在发展方向上,当下一部分大模型已经聚焦到垂类领域应用。基于成千上万的模型发展,底座或许会发生改变,但仔细一想,也总需要有人能够在垂类行业中跑出来。
同时,在发展初期,虽然闭源大模型在质量上更优,也相对安全,但大模型生态终究需要一定程度的内卷,开源实际上可以助长大模型的繁荣。另一个角度,基于开源众多企业有了赛道参赛的资格,但也总有人轻易就倒在了第一关匣——算力短缺。
说到底,大模型数量是在以倍数的数量在增长,但如果片面的看待大模型日益增长的数量,那么某种程度上也会忽略掉背后部分公司对大模型的抉择、挣扎,甚至是选择后放弃的可能性。
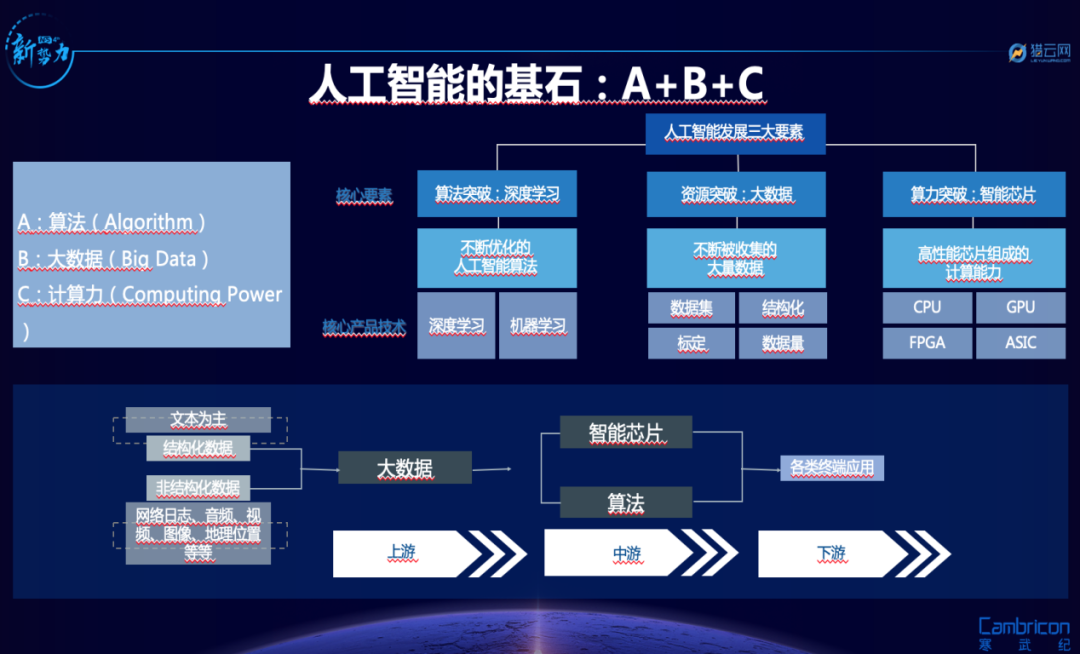
众所周知,人工智能三要素是:算力、算法和数据。开源只是处于算法阶段,之后企业还需要对其进行大量的算力支持和数据训练,这背后的成本是高昂的。
 垂直大模型,创业公司还有盼头吗?
垂直大模型,创业公司还有盼头吗?
在开源大模型选择上,基于成本和定制开发的原因,选择小参数模型的创业型企业不在少数,甚至是该类企业的首选。
一个是预训练成本问题。
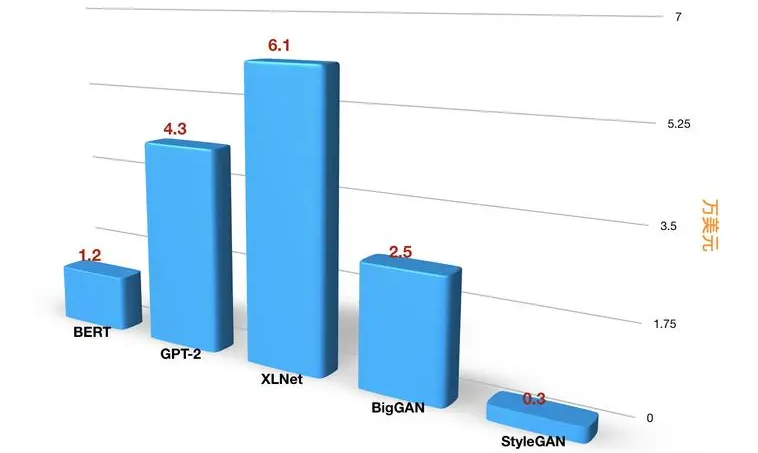
国盛证券曾经估算,GPT-3训练一次的成本约为140万美元,对于一些更大的LLM模型,训练成本介于200万美元至1200万美元之间。
包括在今年1月,平均每天约有1300万独立访客使用ChatGPT,对应芯片需求为3万多片英伟达A100GPU,初始投入成本约为8亿美元,每日电费在5万美元左右。
更何况,在大量资金投入之前,还需要大量的数据资源来支撑模型训练。为此,另一个原因是预训练需求问题。
有业内也曾表达过对此的看法:“大模型本身的泛化能力仍受限于数据。”

因为如果一旦对大模型的高质量数据筛选和训练得过少,大模型的输出质量问题是很明显的,在体验上,用户的体验感也会大大降低。
可以说,在预训练的过程中,仅仅是在数据的积累上就已经花费了大量的资金与时间。
更何况,在大模型赛道中,大多数的创业公司都是围绕在行业垂直领域进行发展,付出虽然相对少,但一定不轻松。
具体一点来说就是,如果大模型要改变行业的商业模式的话,那么对此最简单的判定标准就是,该类大模型是否具备的行业数据足够多,例如要对藏在暗处的黑产要有足够的了解,才能不被黑产所用,处于安全被动的状态。
另一个判定的标准就是,大模型在运行之时所处理的数据,最终输出的质量如何。
说到底,想要基于开源模型去打破模型垄断,还需要对大量的数据进行足够的优化提升,并且对基础设施的投入足够完善。
如今的开源大模型实际上更像是网络时代的Android,没有大厂的落地场景、数据积累等优势的创业公司,发展起来很不容易,但仍然存在机会。
事实上,达摩院也曾将“大小模型协作发展”视为未来趋势之一。
就连创业公司追一科技相信“垂直大模型是坚实的机会,就像发现美洲大陆这件事远不只成就了一人而已”。

于是如今我们可以看到众多创业公司开始选择入局大模型赛道,其中包括毫末智行、创新奇智、元语智能等AI创业公司所推出的DriveGPT雪湖·海若、奇智孔明、ChatYuan元语等大模型。
不过,国内虽然尚未有产品面向C端,但基于B端,大厂已经开始实现初步落地的过程中。
据悉,目前大厂都在计划通过云的方式对外输出大模型的能力,云计算成为A大模型落地的最佳方式,模型即服务(MaaS)越发受到关注,而这也将带来大模型成本的降低。
那么,创业公司还存在盼头吗?


根据权威杂志《Fast Company》预测,OpenAI 2023年的收入将达到2亿美元,包括提供API数据接口服务、聊天机器人订阅服务费等。
很显然,各行业对大模型的需求是存在的,但基于安全性的考虑,加之to B对大模型亦步亦趋的态度,大模型当下安全系数有限。于是,在相对基础,需求量高的对话、文档内容生成、问答,包括协同办公中对话、文档生成等众多场景,互联网大厂也在优先做。
例如,现在人类只需要把商品的信息告诉AI,让AI自动生成多种风格的商品带货脚本和风格,再配个数字人主播,就可以帮企业把货给卖出去。据百度介绍,相比真人直播,数字直播可实现7*24小时不间断直播,转化率为无人直播间的2倍。
在云上基础设施作为大模型创业的必要底座下,拥有云计算的互联网大厂具有一定的优势。
根据IDC发布的2022年全球云计算IaaS市场追踪数据来看,市场份额TOP10玩家都是中美的大公司,包括美国的亚马逊、谷歌、微软、IBM,中国的阿里、华为、腾讯、百度等。

虽然大模型的开闭源之争,终究不会是靠某一个或几个产品的出现而终结,还要更多顶尖人才参与、技术迭代和资金支持。
但横做对比,众多AI创业公司也缺少了一份如同创业独角兽公司MiniMax的运气。(不同的是MiniMax注重的是通用大模型)
7月20日,腾讯云对外披露助力MiniMax研发大模型的最新进展。目前,腾讯云长期支持MiniMax的千卡级任务稳定运行在腾讯云上,可用性达99.9%。
据悉,自2022年6月起,基于算力集群、云原生、大数据、安全等产品能力,腾讯云为MiniMax搭建了从资源层、数据层到业务层的云架构。
现实似乎再度证明了,拿到入场券是第一步,接下来考验的是市场玩家们探索商业化和技术升级的能力。直白一点来说,AI创业公司想要在赛道中跑到最后,每一步都不能落下。

某种程度上来说,在大模型研发上创业公司也并非全无优势。
虽然部分互联网大厂已经实现初步场景落地,亦或是开始售卖服务获得收入,但大厂以及MiniMax的目光更多是聚焦在通用大模型上。
而垂直大模型仍然是真空地带。特别是对于传统企业群体来说,考虑到自身业务的IT属性低、投出产比低等问题,选择自研大模型的概率较低。
例如创新奇智聚焦在工业大模型产品“奇智孔明”;拥有一定数据优势,往语言上发展的ChatYuan元语大模型;主打自动驾驶生成式大模型DriveGPT雪湖·海若。
不过有一说一 ,训练的数据和方向不同,成本差别很大。
先是元语大模型从零开始做一次训练的成本能做到千万人民币量级。而在自动驾驶生成式领域上,比ChatGPT 多设计一套新的语言,紧接着再把所有的真实道路驾驶数据,并“翻译”成统一的语言的DriveGPT雪湖·海若,也存在着一定的成本投入。
某种程度上,AI创业公司能够实现对大模型的大量投入,更多的是得益于ChatGPT商业和营销方面的成功,能够瞬间让人们目睹了大模型的可落地性,而不是继续隐匿在漫长的技术迭代中。
为此,当下实现落地的第一步,就是大模型的训练成本、推理成本一定能做到比搜索还要低,而且还能保证即时性。

有观点认为,能跑出来的中国大模型创业公司,很可能是垂直整合型。
简单来说就是,一边在做底层大模型的同时,找准一个模型最终的主应用场景,一边收集用户数据并做出快速的迭代。
目测,元语智能更偏向于这一类。总结起来看,在很长的一段时间内元语智能都聚焦在自然语言大模型业务上。
元语COO朱雷并表示,“不会为了跟风盲目拓展图片、视频业务,元语的目标是实现‘ChatGPT’等前沿语言大模型的全面国产化。语言大模型的生态已经足够大了,做好业务聚焦很重要。”
但对于其他往自动驾驶、工业生产等垂直大模型发展的创业公司来说,或许缺乏对一些特殊的行业数据掌握。

毕竟,在垂直大模型赛道,未来企业竞争的一个核心因素,就是私有数据和私有经验,个体公司的流程并不被大模型者知晓时,可能就会有独特的竞争力。
另外,业务聚焦的过程中,还需要到数据从源头到预训练、输出的准确性。
目前,生成式人工智能在监管上也正在受到更多关注。近日国内发布了 《生成式人工智能服务管理办法(征求意见稿)》,明确要求不得出现歧视,生成内容应当真实准确、防止生成虛假信息等,如果出现,除内容过滤外,还要通过模型优化等进行优化。
但如果是作为生成式人工智能的固有缺陷,这在从技术上难以保证和彻底解决。
此外,在更好的开源模型的出现,保不齐会伴随着更多跃跃欲试的公司会涌进来,这对于创业公司来说,有何尝不是竞争?
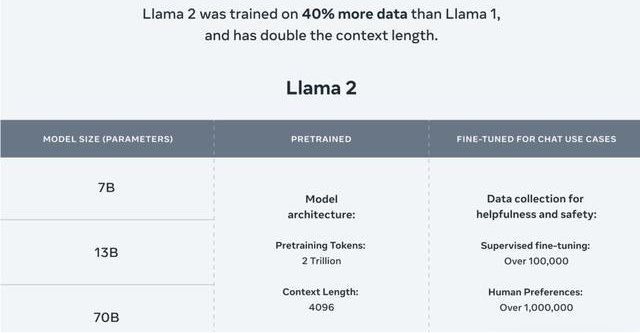
例如当下的Llama 2,7月18日,Meta公司发布了首个开源人工智能模型Llama的商业版本 Llama 2。有企业认为,根据现在的各种评测文档,除了代码能力差一些,其实很多地方已经开始接近ChatGPT。
或许未来开源社区的狂热浪潮会让具备基础能力的大模型普及化,以后私有化大模型就是白菜价。直白一点来说就是,企业可能会非常便宜地使用私有化大模型。
更重要的一个点是,汤道生曾表示:“通用大模型有很强的能力,但并不能解决很多企业的具体问题,在100个场景中可以解决70%—80%的问题,但未必能100%满足企业某个场景的需求。但企业如果基于行业大模型,再加上自身数据进行精调,可以建构专属模型,打造出高可用的智能服务。”
当然,这种私有化大模型还未到来,但赛道中的创业公司,一定是机遇和困境齐具。
 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握



