

谷歌人机验证已经拦不住AI了!
最新多模态大模型,能轻松找到图中所有交通信号灯,还准确圈出了具体位置。

表现直接超越GPT-4V。

这就是由苹果和哥伦比亚大学研究团队带来的多模态大模型“雪貂”(Ferret)。

它具备更强的图文关联能力,提升了大模型在“看说答”任务中的精确度。
比如下图中非常细小的部件(region 1),它也可以分辨出来是避震。
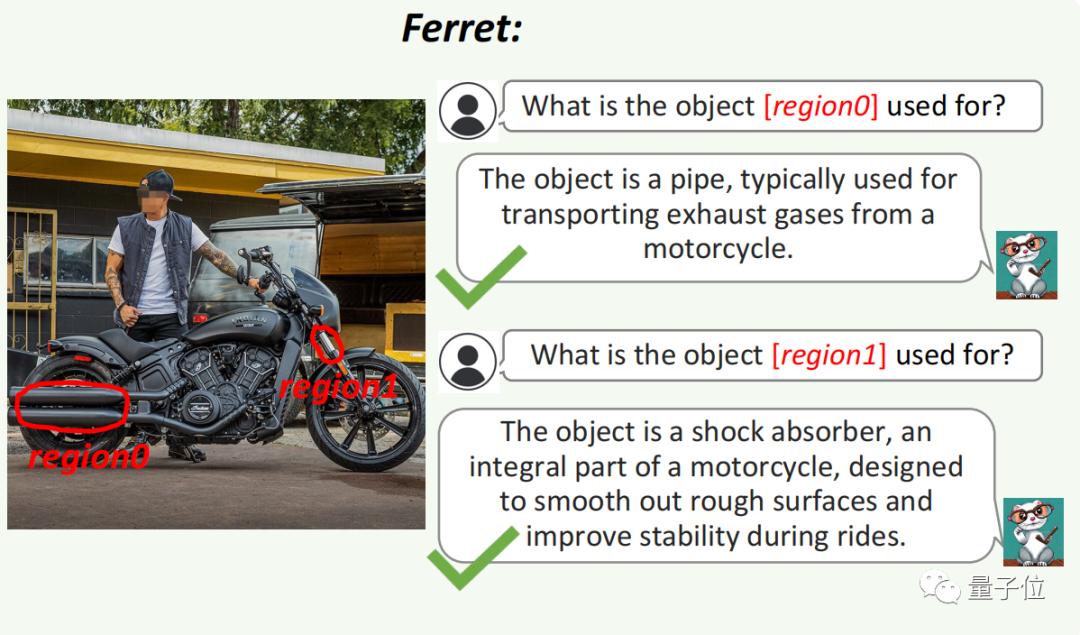
GPT-4V没能回答正确,在细小部分上的表现不佳。

所以,Ferret是如何做到的呢?
01 “点一点”图像大模型都懂
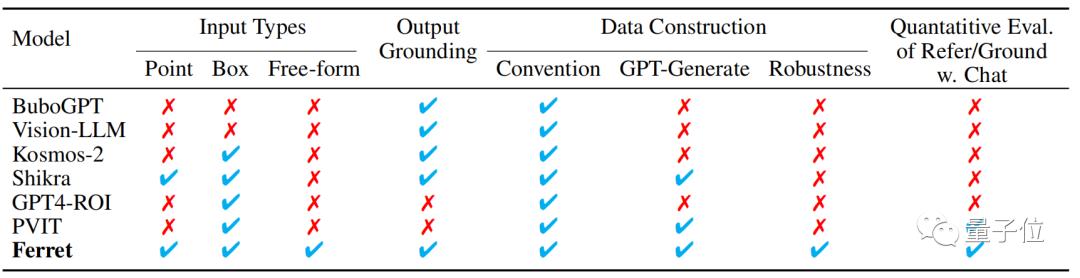
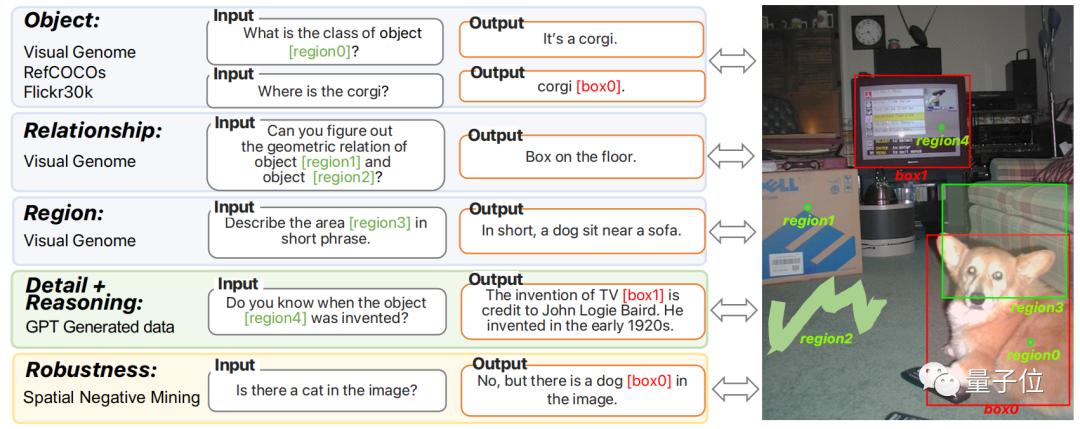
Ferret解决的核心问题是让引用(referring)和定位(grounding)两方面空间理解能力更加紧密。
引用是指让模型准确理解给定区域的语义,也就是指一个位置它能知道是什么。
定位则是给出语义,让模型在图中找到对应目标。
对于人类来说,这两种能力是自然结合的,但是现有很多多模态大模型却只会单独使用引用和定位。
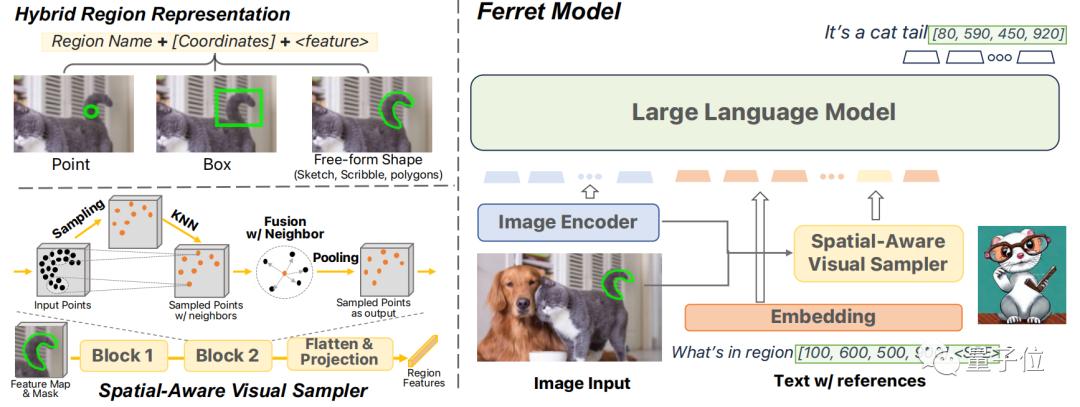
所以Ferret提出了一种新型的混合区域表示方法,能将离散坐标和连续特征联合起来表示图像中的区域。
这样一来,模型就能分辨出边界框几乎一样的对象。
比如下图中两个物体的情况,如果只用离散边界框,模型会感到很“困惑”。和连续的自由形状混合表示相结合,能很好解决这一问题。

为了提取多样化区域的连续特征,论文提出了一种空间感知的视觉采样器,能够处理不同形状之间的稀疏性差异。
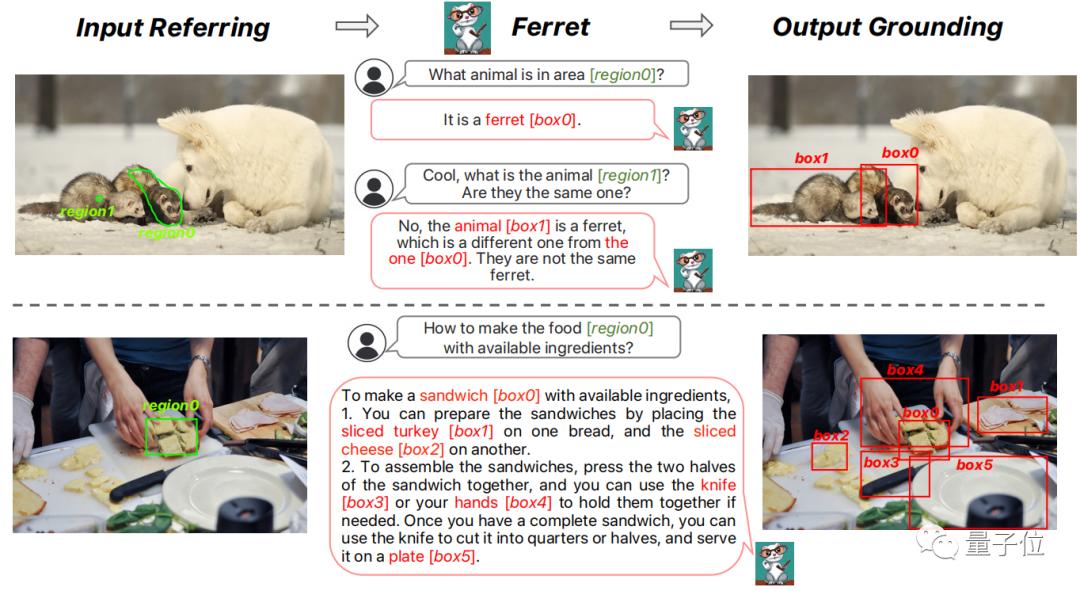
因此,Ferret可以接受各种区域输入,如点、边界框和自由形状,并理解其语义。
在输出中,它可以根据文本自动生成每个定位对象的坐标。
为了实现这一目标,Ferret模型的架构包括图像编码器、空间感知的视觉采样器和语言模型(LLM)等组成部分。
Ferret结合了离散坐标和连续特征,形成了一种混合区域表示。
这种表示方法旨在解决表示各种形状和格式的区域的挑战,包括点、边界框和自由形状。
离散坐标中每个坐标都被量化为一个目标框的离散坐标,这种量化确保了模型对不同图像大小的鲁棒性。
而连续特征则由空间感知视觉采样器提取,它利用二进制掩码和特征图在ROI内随机采样点,并通过双线性插值获得特征。
这些特征经过一个由3D点云模型启发的空间感知模块处理后,被浓缩成一个单一的向量, 并映射到大型语言模型(LLM)进行下一步处理。
为了增强Ferret的能力,论文还创建了一个名为GRIT的数据集。
这个数据集包含1.1M个样本,涵盖了个体对象、对象之间的关系、特定区域的描述以及基于区域的复杂推理等四个主要类别。
GRIT数据集包括了从公共数据集转换而来的数据、通过ChatGPT和GPT-4生成的指令调整数据,并额外提供了95K个困难的负样本以提高模型的鲁棒性。
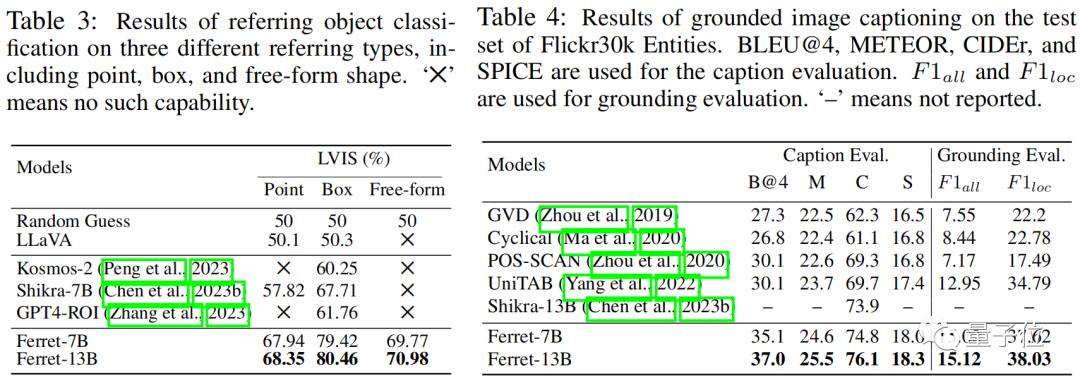
实验结果表明,该模型不仅在经典的引用和定位任务中表现出优越性能,而且在基于区域和需要定位的多模态对话中远远超过现有其他MLLM模型。
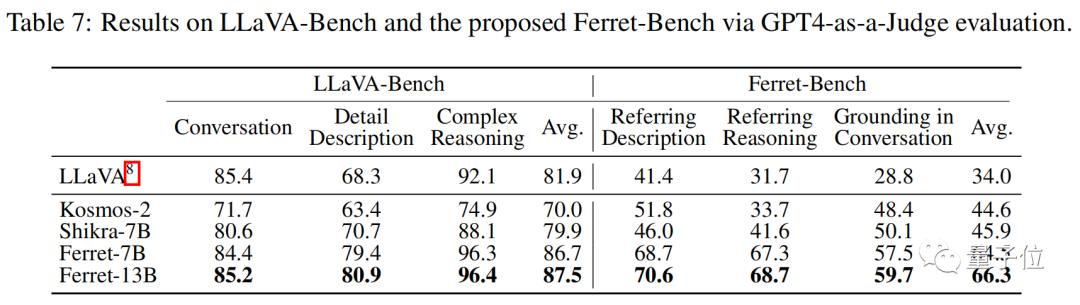
此外,研究还提出了Ferret-Bench,可以评估图像局部区域的引用/定位、语义、知识和推理能力。
Ferret模型在LLaVA-Bench和Ferret-Bench上进行评估,在所有任务中都表现出色,特别是在需要指代和视觉grounding的三个新任务上,Ferret的表现很出色。
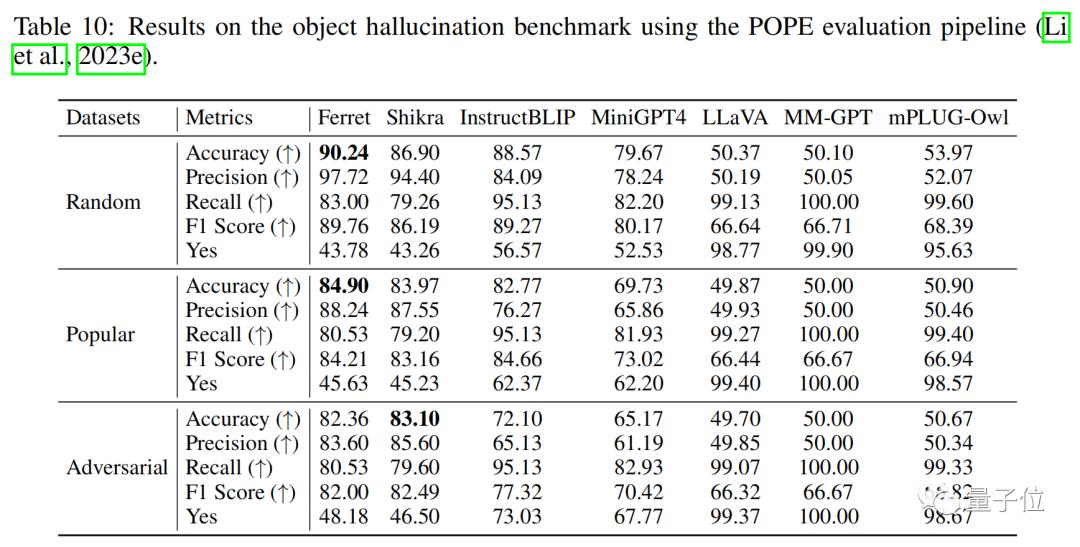
而且在描述图像细节上有明显提升,幻觉有明显下降。
02 全华人团队
Ferret大模型由苹果AI/ML和哥伦比亚大学研究团队共同带来,全华人阵容。
有昊轩和张昊天为共同一作。
有昊轩现在为哥伦毕业大学计算机科学博士,毕业后将加入苹果AI/ML团队。2018年从西安电子科技大学本科毕业。
主要研究方向为视觉语言理解、文本-图像生成和视觉语言。
张昊天现在为苹果AI/ML团队视觉智能研究员。
在加入苹果之前,张昊天在华盛顿大学获得博士学位,本科毕业于上海交通大学。
他是GLIP/GLIPv2的主要作者之一,GLIP曾获得CVPR2022的Best Paper Award的提名。

此外团队成员还包括甘哲、王子瑞、曹亮亮、杨寅飞等前谷歌和微软的多位优秀的多模态大模型研究员。
 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握



