最近,AI大模型创业公司零一万物被指套壳Meta开源大模型LLaMA,在圈子里闹得沸沸扬扬。连带着素有国内“AI教父”之称的李开复也卷入风波中。事件的起因源于原阿里首席AI科学家、现已在美国创业的贾扬清在朋友圈里的一段感叹。大概意思是:做小公司不容易,希望国内大厂如果就是开源的模型结构,建议就叫原来的名字,免得大家还要做一堆工作,就为了适配你们改名字。贾扬清没有指明道姓,消息一传开,“大厂”究竟指谁众说纷纭,一波或多或少基于Llama“魔改”的国产大模型纷纷躺枪。不过最终很多事实细节都指向了李开复创办的零一万物刚发布的首款预训练大模型Yi-34B。
-1-
近日,网络上流传着一张原阿里首席 AI 科学家贾扬清的朋友圈,称某国产大模型实际上是抄袭的LLaMA,但为了表示不一样,把代码里的名字换成了自己的名字,然后宣称是自己研发。
事情迅速发酵。11月15日,“零一万物”在公众号发文对此进行了回应称,“对于沿用LLaMA部分推理代码经实验更名后的疏忽,原始出发点是为了充分测试模型,并非刻意隐瞒。”
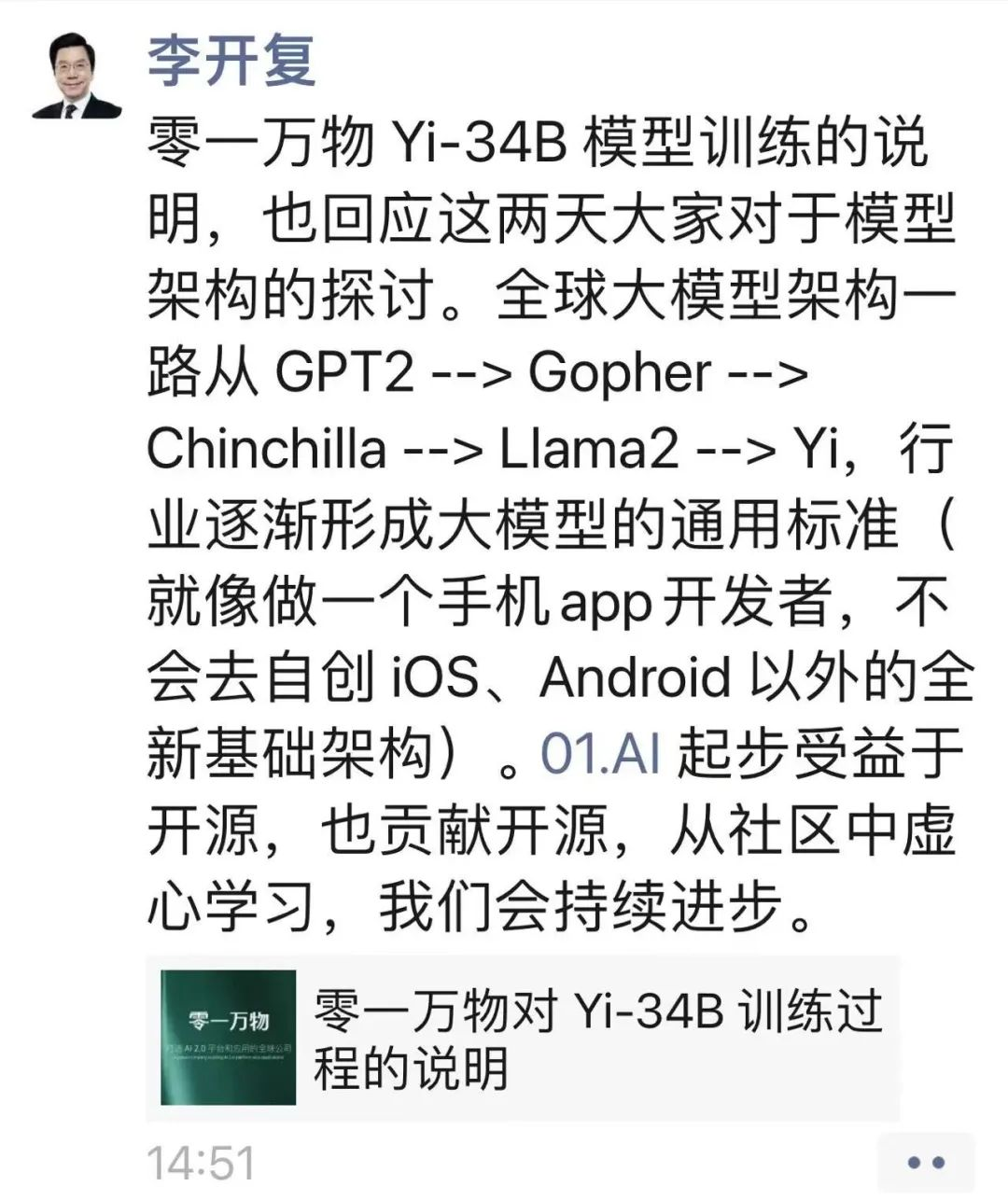
其实,在贾扬清站出来爆料之前,有关零一万物模仿LLaMA架构的指控已经开始在开源社区内发酵。在Hugging Face 开源主页上,某国外高级人工智能应用专家埃里克·哈特福德在Huggingface上发帖称,“Yi-34B 模型基本采用了LLaMA的架构,只是重命名了两个张量。”11月14日,Yi团队开源总监Richard Lin在该帖下回复称,哈特福德对张量名称的看法是正确的,零一万物将把它们从Yi重命名为Llama。可以看出,这几份回应中,零一万物都提到了是自己的“疏忽”或是在发布之前“有点失误”。尽管零一万物已经公开承认其借鉴了LLaMA架构,但似乎并不能就此直接给零一万物的大模型扣上“套壳”或者“抄袭”的帽子。零一万物在对Yi-34B训练过程的说明中表示,模型训练过程好比做一道菜,架构只是决定了做菜的原材料和大致步骤……其投注了大部分精力调整训练方法、数据配比、数据工程、细节参数、baby sitting(训练过程监测)技巧等。不过,这场“误会”不禁让人回想起李开复曾经发表的一段话:“零一万物坚定进军全球第一梯队目标,从招的第一个人,写的第一行代码,设计的第一个模型开始,就一直抱着成为‘World's No.1’的初衷和决心。我们组成了一支有潜力对标 OpenAI、Google等一线大厂的团队,经历了近半年的厚积薄发,以稳定的节奏和全球齐平的研究工程能力,交出了第一张极具全球竞争力的耀眼成绩单。Yi-34B可以说不负众望,一鸣惊人。”
-2-
创投圈对李开复并不陌生。他是计算机科学家出身,职业生涯起点很高,曾先后任职于微软、谷歌等,后来创立了创新工场,在创投圈颇有盛名。
李开复结缘于AI,要追溯到几十年前。早在1982年,李开复在申请攻读卡内基梅隆大学研究生时就曾写道,他想把自己的一生奉献给AI研究。后来他还写了两本畅销书:《AI·未来》和《AI 2041》。靠着数十年如一日对AI的宣扬布道,李开复一度被称为中国的“AI教父”。今年3月,在国内大模型浪潮风起云涌之际,李开复博士“撸起袖子”亲自带队,开始组建团队,研发通用大模型。三个月之后,该公司启动运营,并正式定名为“零一万物”,李开复担任CEO,“在全球范围号召世界级人才”。据了解,零一万物已拥有一支超过100人的专业团队。算法和产品团队背景均来自国内外大厂,如Google、微软、阿里巴巴、百度、字节跳动、腾讯等国内外大厂。团队成员中,技术副总裁及AI Alignment负责人是 Google Bard/Assistant 早期核心成员,主导或参与了从 Bert、LaMDA 到大模型在多轮对话、个人助理、AI Agent 等多个方向的研究和工程落地;首席架构师曾在Google Brain与Jeff Dean、Samy Bengio等合作,为TensorFlow的核心创始成员之一。而算法和模型团队成员中,有论文曾被GPT-4引用的算法大拿,有获得过微软内部研究大奖的优秀研究员,曾获得过阿里CEO特别奖的超级工程师。总计在ICLR、NeurIPS、CVPR、ICCV等知名学术会议上发表过大模型相关学术论文100余篇。零一万物技术副总裁及 Pretrain 负责人黄文灏、技术副总裁及AI Infra负责人戴宗宏也是主力战将。黄文灏曾先后任职于微软亚洲研究院和智源研究院;戴宗宏则是前华为云 AI CTO 及技术创新部长、前阿里达摩院 AI Infra 总监。创立至今不到8个月时间里,零一万物交出了第一份答卷。就在10天之前,11 月 6 日,零一万物刚发布了“Yi”系列开源大模型——Yi-34B和Yi-6B,两者的区别在于,Yi-6B适合个人及研究用途,而Yi-34B已经具备大模型涌现能力,适合发挥于多元场景,满足开源社区的刚性需求。两者目前都已开放免费商用申请。零一万物团队声称Yi-34B在通用能力、知识推理、阅读理解等多个核心指标上均达到世界第一梯队水平。李开复也曾充满信心地表示,Yi-34B的目标是成为“全球最强开源模型”。据“零一万物”官方公众号称,据大模型社区Hugging Face评测,Yi成为全球开源大模型“双料冠军”,是迄今为止唯一登顶该社区全球开源模型排行榜的国产模型。据媒体报道,零一万物已完成由阿里云领投的新一轮融资,投后估值超10亿美元,跻身中国大模型创业公司独角兽行列。
-3-
今年以来,国内AI产业风起云涌,号称要自研大模型的大厂和创业团队前赴后继。
据悉,中国研发的大模型数量全球第二,10亿参数规模以上的大模型已发布79个。不过,这里的“大模型”并非全指“自研大模型”,也包含了许多借鉴国外开源大模型的非自研模型。虽然国产大模型仍在努力追赶ChatGPT的步伐,但不可否认的是与OpenAI更先进模型,差距有逐渐扩大的趋势。在11月6日的开发者大会上,OpenAI创始人阿尔特曼推出了GPT-4版本GPT-4 Turbo,性能更为强大,价格直接打“骨折”。OpenAI推出的定制版GPT和简化开发API的工具Assistant API更是引发AI圈一阵骚动。利用Assistant API,用户可以不懂编程,直接用自然语言就可以设计特定用途的GPT和开发插件。这无疑令一众依托OpenAI基础大模型进行“套壳”开发的创业公司,以及简化开发过程的中间件公司感受到生死存亡的压力。所以,在ChatGPT引发的新一轮AI颠覆性变革现实面前,不得不让人开始重新打量中美在AI方面的差距。阿尔特曼带领OpenAI一路狂飙。今年10月份,他首次对外明确,OpenAI已经启动GPT-5、GPT-6的训练,并将继续沿着多模态方向持续迭代。虽然基础大模型中国稍微逊色,但是中国在AI应用的开发商并不一定就会落后。AIGC时代将诞生比移动互联网大十倍的平台机会,将出现把既有的软件、使用界面和应用重写一次,改写用户交互和入口的新机遇。李开复曾表示,“AI 2.0是有史以来最大的科技革命,它带来的改变世界的最大机会一定是平台和技术,正如PC时代的微软Office,移动互联网时代的微信、抖音、美团一样,商业化爆发式增长概率最高的一定是ToC应用。”百度创始人李彦宏也在最近的思考中所说,人类进入AI时代的标志,是出现大量的AI原生应用,而不是出现大量的大模型。无论是中国还是美国,最好的原生应用还没出来,这恰恰是创业者千载难逢的机会。



 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握


 微信好友
微信好友
 朋友圈
朋友圈
 鞭牛士公众号
鞭牛士公众号
 鞭牛士微博
鞭牛士微博