财报发布前两天,英伟达突然冒出来一个劲敌。
一家名叫Groq的公司今天在AI圈内刷屏,杀招就一个:快。在传统的生成式AI中,等待是稀松平常的事情,字符一个个蹦出,半天才能回答完毕。但在Groq今天开放的云服务体验平台上,你看到的会是一秒一屏。当模型收到提示后,几乎能够立即生成答案。这些答案不仅真实可信,还附有引用,长度更是达到数百个单词。
电子邮件初创企业Otherside AI的首席执行官兼联合创始人马特·舒默(Matt Shumer)在演示中亲自体验了Groq的强大功能。他称赞Groq快如闪电,能够在不到一秒钟的时间内生成数百个单词的事实性、引用性答案。更令人惊讶的是,它超过3/4的时间用于搜索信息,而生成答案的时间却短到只有几分之一秒。
虽然今天才刷屏,但Groq公司并非初出茅庐的新创企业。实际上,该公司成立于2016年,并在那时就注册了Groq商标。去年11月,当马斯克发布人工智能模型Grok时,Groq公司的开发者们就发了一篇文章说马斯克撞名自己的公司。信写的挺逗的,但这波流量他们是一点没吃到。
这一次他们之所以能突然爆发,主要是因为Groq云服务的上线,让大家真的能亲身感受一下不卡顿的AI用起来有多爽。
有从事人工智能开发的用户称赞,Groq是追求低延迟产品的“游戏规则改变者”,低延迟指的是从处理请求到获得响应所需的时间。另一位用户则表示,Groq的LPU在未来有望对GPU在人工智能应用需求方面实现“革命性提升”,并认为它可能成为英伟达A100和H100芯片的“高性能硬件”的有力替代品。
Groq芯片
能在速度上取胜的核心技术是LPU
根据其模型的首次公开基准测试结果,Groq云服务搭载的Llama2或Mistreal模型在计算和响应速度上远超ChatGPT。这一卓越性能的背后,是Groq团队为大语言模型(LLM)量身定制的专用芯片(ASIC),它使得Groq每秒可以生成高达500个 token。相比之下,目前ChatGPT-3.5的公开版本每秒只能生成大约40个token。
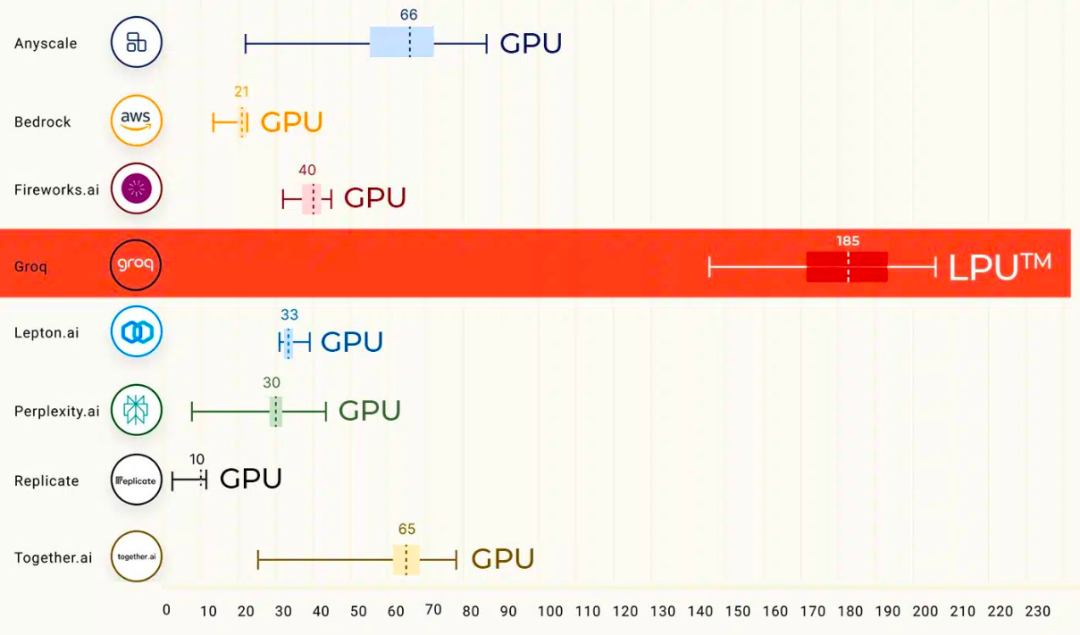
这一芯片能在速度上取胜的核心技术是Groq首创的LPU技术。根据推特上与Groq关系密切的投资人k_zeroS分享,LPU的工作原理与GPU截然不同。它采用了时序指令集计算机(Temporal Instruction Set Computer)架构,这意味着它无需像使用高带宽存储器(HBM)的GPU那样频繁地从内存中加载数据。这一特点不仅有助于避免HBM短缺的问题,还能有效降低成本。不同于Nvidia GPU需要依赖高速数据传输,Groq的LPU在其系统中没有采用高带宽存储器(HBM)。它使用的是SRAM,其速度比GPU所用的存储器快约20倍。
鉴于AI的推理计算相较于模型训练需要的数据量远小,Groq的LPU因此更节能。在执行推理任务时,它从外部内存读取的数据更少,消耗的电量也低于Nvidia的GPU。
如果在AI处理场景中采用Groq的LPU,可能就无需为Nvidia GPU配置特殊的存储解决方案。LPU并不像GPU那样对存储速度有极高要求。Groq公司宣称,其技术能够通过其强大的芯片和软件,在AI任务中取代GPU的角色。
另一位安卡拉大学的助教更形象的解释了一下LPU和GPU的差别,“想象一下,你有两个工人,一个来自Groq(我们称他们为“LPU”),另一个来自Nvidia(我们称之为“GPU”)。两人的任务都是尽快整理一大堆文件。
GPU就像一个速度很快的工人,但也需要使用高速传送系统(这就像高带宽存储器或HBM)将所有文件快速传送到他们的办公桌上。这个系统可能很昂贵,有时很难得到(因为HBM产能有限)。
另一方面,Groq的LPU就像一个高效组织任务的工人,他们不需要那么快地交付文件,所以用了一张就放在他们身边的更小的桌子(这就像SRAM,一种更快但更小的存储器),所以他们几乎可以立即获得所需的东西。这意味着他们可以在不依赖快速交付系统的情况下快速工作。
对于不需要查看堆中每一篇文件的任务(类似于不使用那么多数据的人工智能任务),LPU甚至更好。它不需要像往常一样来回移动,既节省了能源,又能快速完成工作。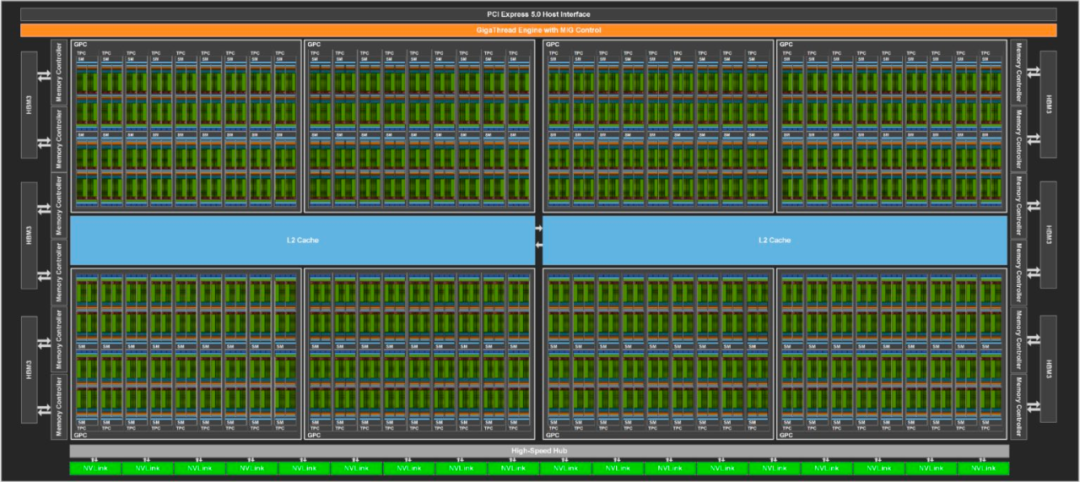 LPU结构
LPU结构
LPU组织工作的特殊方式(这是时态指令集计算机体系结构)意味着它不必一直站起来从堆里抢更多的论文。这与GPU不同,GPU不断需要高速系统提供更多的文件。”运用LPU这一技术,Groq生产了加速器单元,根据其网站介绍规格如下: 其特殊内存SRAM的容量是230MB,带宽80TB/s,在INT8、FP16下算力为188TFLOPs。
其特殊内存SRAM的容量是230MB,带宽80TB/s,在INT8、FP16下算力为188TFLOPs。
确实快,但是贵,
目前并不能成为英伟达的竞争对手
在Groq刚刚刷屏的时候,AI行业都沉浸在它闪电速度的震撼之中。然而震撼过后,很多行业大佬一算账,发现这个快的代价可能有点高。贾扬清在推特上算了一笔账,因为Groq小的可怜的内存容量(230MB),在运行Llama-2 70b模型时,需要305张Groq卡才足够,而用H100则只需要8张卡。从目前的价格来看,这意味着在同等吞吐量下,Groq的硬件成本是H100的40倍,能耗成本是10倍。
芯片专家姚金鑫(J叔)向腾讯科技进行了更详细的解释: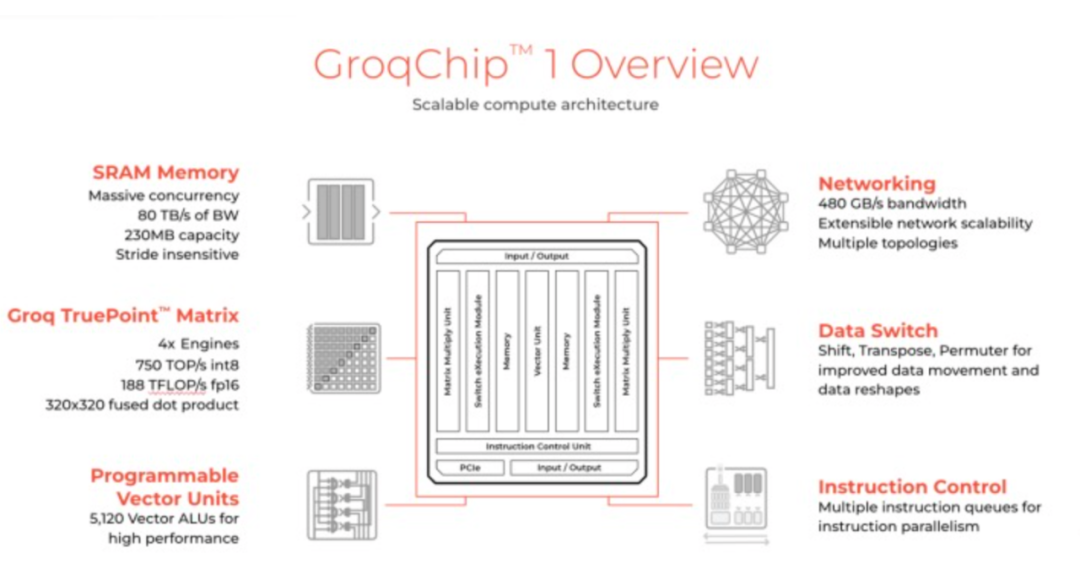
从芯片的规格中,可以看到几个关键信息点:SRAM的容量是230MB,带宽80TB/s,FP16的算力是188TFLOPs。按照当前对大模型的推理部署,7B的模型大约需要14G以上的内存容量,那么为了部署一个7B的模型,大约需要70片左右的芯片,根据透露的信息,一颗芯片对应一张计算卡,按照4U服务器配置8张计算卡来计算,就需要9台4U服务器(几乎占了一个标准机柜了),总共72颗计算芯片,在这种情况下,算力(在FP16下)也达到了惊人的188T * 72 = 13.5P,如果按照INT8来算就是54P。54P的算力来推理7B的大模型,用大炮打蚊子来形容一点也不为过。目前社交媒体广泛传播的文章对标的是英伟达H100,其采用的是80G的HBM,这个容量可以部署5个7B的大模型实例;我们再来看算力,稀疏化后,H100在FP16下的算力将近2P,在INT8上也将近4P。那么就可以做个对比,如果从同等算力来看,如果都是用INT8来推理,采用Groq的方案需要9台包含72片的服务器集群,而如果是H100,达到同等算力大约需要2台8卡服务器,此时的INT8算力已经到64P,可以同时部署的7B大模型数量达到80多个。原文中提到,Groq对Llama2-7B的Token生成速度是750 Tokens/s,如果对标的是H100服务器,那这2台总共16颗的H100芯片,并发吞吐就高到不知道哪里去了。如果从成本的角度,9台的Groq服务器,也是远远贵过2台H100的服务器(即使此刻价格已经高到离谱)。● Groq:2万美金*72=144万美金,服务器2万美金*9=18万美金,纯的BOM成本160万美金以上(全部都是按照最低方式来计算)。● H100:30万美金*2 = 60万美金(国外),300万人民币*2=600万人民币(国内实际市场价)如果是70B的模型,同样是INT8,要用到至少600张卡,将近80台服务器,成本会更高。这还没有算机架相关费用,和消耗的电费(9台4U服务器几乎占用整个标准机柜)。实际上,部署推理性价比最高的,恰恰是4090这种神卡。Groq是否真的超越了英伟达?对此,姚金鑫(J叔)也表达了自己不同的看法:“英伟达在本次AI浪潮中的绝对领先地位,使得全球都翘首以盼挑战者。每次吸引眼球的文章,总会在最初被人相信,除了这个原因之外,还是因为在做对比时的“套路”,故意忽略其他因素,用单一维度来做比较。这就好比那句名言“抛开事实不谈,难道你就没有一点错的地方吗?”抛开场景来谈对比,其实是不合适的。对于Groq这种架构来讲,也有其尽显长处的应用场景,毕竟这么高的带宽,对许多需要频繁数据搬运的场景来说,那就是再好不过了。总结起来,Groq的架构建立在小内存,大算力上,因此有限的被处理的内容对应着极高的算力,导致其速度非常快。现在把句话反过来,Groq极高的速度是建立在很有限的单卡吞吐能力上的。要保证和 H100同样吞吐量,你就需要更多的卡。传奇CEO,小团队
虽然Groq还面对着很多潜在的问题,但它还是让人看到了GPU之外的可能路径。这主要得益于其背后的超强团队。Groq的CEO是被称为“TPU之父”的前谷歌员工乔纳森·罗斯;联合创始人道格拉斯·怀特曼也来自谷歌TPU团队,并先后创立了四家公司。该公司首席技术官吉姆·米勒曾是亚马逊云计算服务AWS设计算力硬件的负责人,CMO曾主导了苹果Macintosh的市场发布。 乔纳森·罗斯
乔纳森·罗斯
Groq目前的团队也相对较小,其总部位于加州山景城,该公司仅有180余名员工,甚至还不到英特尔等大型芯片制造商所需工程师数量的四分之一。罗斯等人的目标是在Groq复制他在谷歌的成功经验,打造一个内部芯片项目,引领整个行业向新技术迈进。他希望吸引少数关键客户,通过广泛部署Groq芯片为公司提供稳定的收入来源,推动公司的独立发展。目前,这家初创公司已开始向潜在客户发送样品。“这就像猎杀大象,”罗斯说道,“你只需要少数猎物就能维持自己的生命,尤其在我们还如此弱小的时候。”(转载自:腾讯科技)




 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握



