今年七月,“9.11和9.9谁更大”这个简单的问题,竟让大多数最先进的大模型都翻了车。根据机器之心的测试,15个主流大模型里,有超过一半都没答对。连GPT-4o和Claude 3.5 Sonnet这两个顶尖模型都是一通操作猛如虎,结论全是不靠谱。
这件事,引发了AI圈内关于AI符号理解能力的大讨论。 在论文中,苹果的研究者发现,只要稍稍更改现有测试集里的数字或词,大语言模型的正确率就会显著下降。如果再加上一些新信息,比如多增加一个条件(把小明花100买苹果,拆成花100买苹果和梨),模型的性能则下降地更为明显。 所以他们得到了一个结论:大语言模型更像复杂的模式匹配,而不是真正的逻辑推理。 但是,用修改测试集的方法去证明大模型不会算数,还是有点隔靴搔痒。 还好,近期的两篇论文用更底层的角度去拆解了它背后的模式匹配:大模型绕过了计算规则,在用一种全新方法学数学。这种学习方法和人类基于原理和公式计算的逻辑推理完全不同,更像是AI自己寻找出了某种规律和模式。 更重要的是,研究大语言模型如何处理算术这一最基础的逻辑运算,能帮我们判断AI是否真的具备推理能力。这是生成式AI这波浪潮中最引人注意的一个核心问题,它很可能规定了AI的上限。 想要看大语言模型到底有没有学会数学规律,更直接的方法是教给它规律,看它会不会用。 ● 13 × 24的格子乘法:2 41 02 043 06 12按对角线相加:第一位:0第二位:0+0=0第三位:2+6=8第四位:4+2=6第五位:2结果:312 ● 13 × 24的重复加法:13+13+13+...+13(24次)或24+24+24+...+24(13次) ●13 × 24的埃及乘法:24=16+8所以需要计算:13 × 16=20813 × 8=104最终:208+104=312 也就是说,如果模型是按我们理解的计算方法做题的话,它一定是沿着这几种部分积的方式去解决乘法问题。 作者对此做了个实验。挑选了两个小开源模型Gemma-22B和 Llama-3.1-8B,先用完整的乘法任务训练模型(如 13 × 34 = 442),然后测试模型是否能识别各个部分积(如 13 × 30 = 390)。结果发现,经过训练的模型对除了重复加法之外的“部分积”识别能力都有增强。



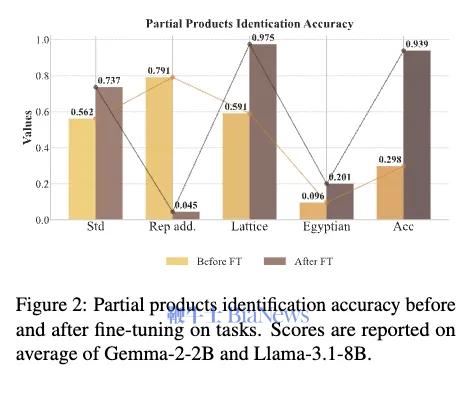
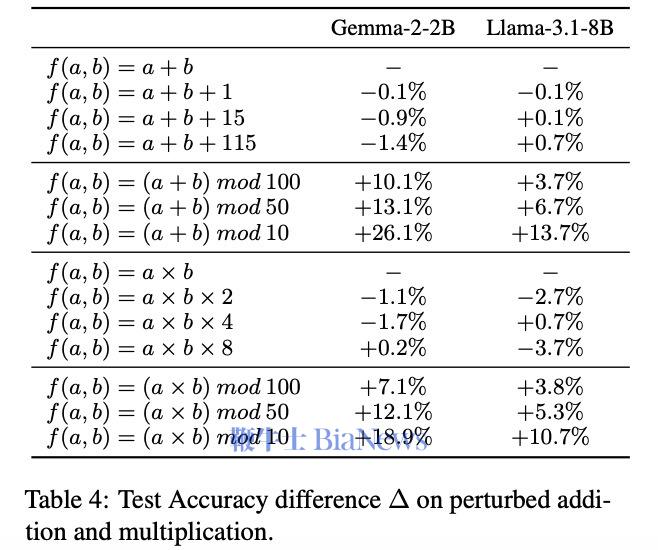
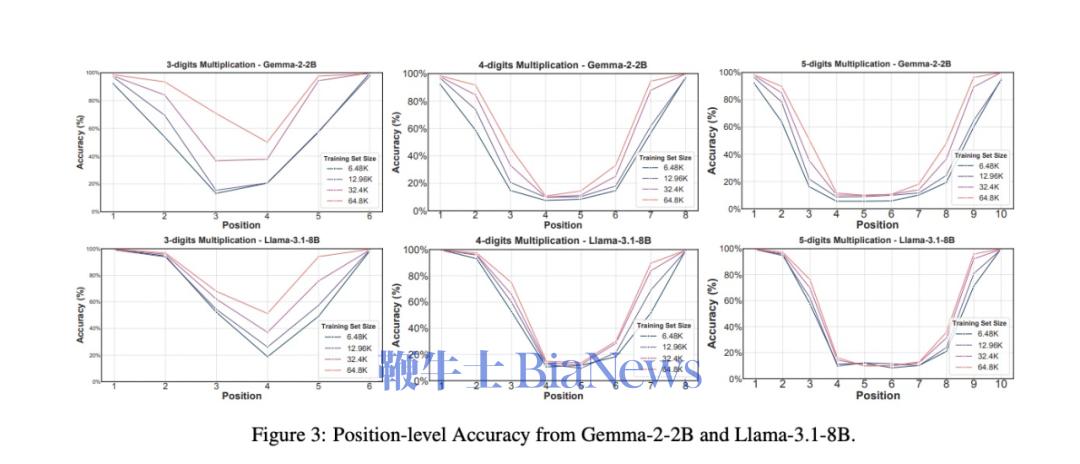
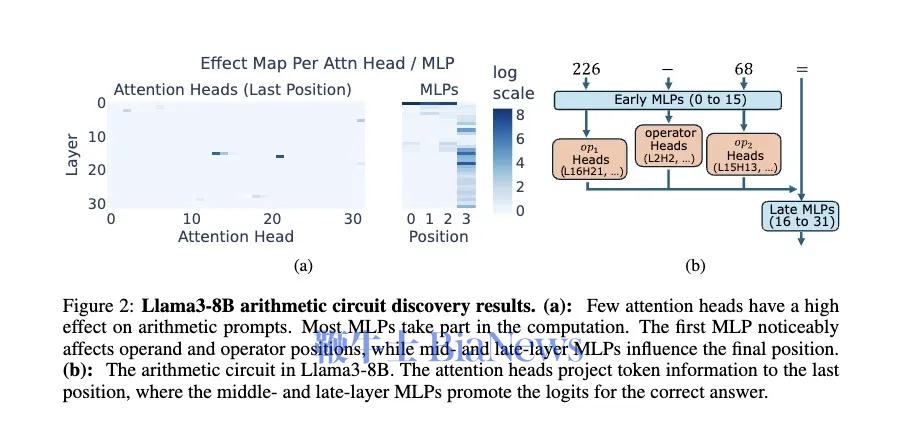
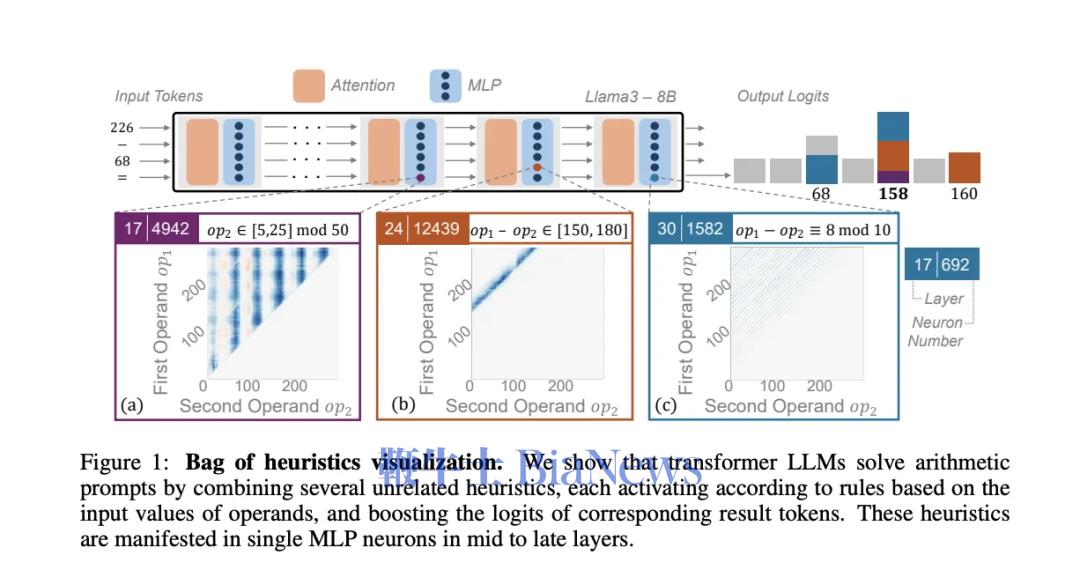
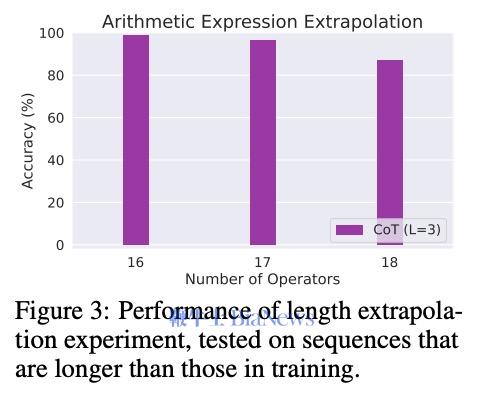
为了继续验证,文章作者先把“部分积“这部分教给模型,再让它做对应的完整乘法题。按照上面的理论,如果模型真的学会了乘法计算,那应该做完整题目的正确率也大幅上升。结果不但没有,正确率还比训练之前低了。 (上面一列是先教完整的,去识别部分积,结果都是增加;下面一列是先教部分积,让模型再算完整的乘法,结果都是减少) 这就证明了,模型确实没有用我们人类常用的计算方法(部分积)的方法在做乘法题。因为,如果模型真的在使用部分积计算,那它会选择一种特定的计算方法。而教给它部分积,它应该能更好地完成计算。 那大模型到底是按什么逻辑在做题呢? 它有一套自己的底层逻辑进行数学运算,叫自回归预测。 自回归预测就是每一步预测都只预测一个位置,并依赖前面的结果。算 13 × 34 = 442,它要先得出个位的2,再得出第二位4,最后得出百位的1。 而在数学中,有一种方法的操作逻辑和这个很像,叫子群法(Subgroup)。它就是把计算中的每个位数都拆成一种对结果某个位数的映射关系。 比如,在两位数乘法 A₁A₂ × B₁B₂ = C₁C₂C₃C₄ 中,可以把任意的A₁,A₂,B₁,B₂的子集和C₁,C₂,C₃,C₄的子集建立起一些对应的映射关系。(A₁,B₁) → C₁ 就是其中一个子群。这个映射会单独的推出C₁,C₂,C₃,C₄的每个数,和自回归非常相似。 (在本图右边,通过A1、A2推C1,用B1,B2推C4,这就是两个子群) 这种方法基本上就是找数字对应的一种规律,而非计算。在本质上还是统计性的规律。就是根据每位数学符号在子集中出现的位置,去寻找它对应的数字出现的规律。 而当一个乘法计算可以拆出来的子群越简单的时候,你越容易找到映射中的对应规律。所以作者只要证明,子群越复杂,大语言模型越不容易算对就可以证明它就是用这种方法去做数学题的。 作者用了三个维度去定义子群的复杂度: ● 子群质量越低,子群越复杂 Moduler方法: 就是限制结果在X个数字中,mod 10就是0-9这是个数字 普通乘法: 12 × 34 = 408 这种子群复杂度越低,模型的正确率越高的情况,就说明了模型确实是很有可能按照子群的逻辑去算算数的。 虽然传统方法解释不通,但按子群的逻辑,这就是完全合理的。 因为首位(C₁)主要由参与乘法的两个数中最高位数字决定,末位(C₅)则是主要由个位数字决定,这两位映射关系简单。越靠中间位置的数字越需要考虑多个输入位的组合,映射关系复杂,子群质量低。因此,其正确率就是按U型分布的。 这一套证明下来,基本可以断定:大模型在数学运算中并没有用到我们熟知的计算规则,而是在自行发现一些符号上对应的统计学规则。论文作者将其成为“符号学习者”,而非“逻辑学习者”。 另一篇同样发表在10月末的论文就在试图更进一步找到这些语言模型运算的规则。 那这些MLP层在进行着怎么样的数据预测呢?作者举了个例子,针对226 - 68 = 158这个减法运算而言,它一共经过了三个可识别的神经元。第一个是检测第二个数68是否在模50余[5,25]的范围内(就是指把一个数除以50后,余数是否在5到25之间);第二个是检测这个答案是否在[150,180]的范围内;第三个则是检测检测这个减法过程结果除以10的余数是否为8。最后,满足这三个条件的数只有158。 这套计算方法看起来和我们的正常逻辑完全不一样,就算是统计规则也是一套非常绕弯子的规则,完全不按套路出牌。但这就是大模型在做数学计算时运用的一系列规则。 论文作者把它们称为”启发式规则“,因为它们最多能启发大模型去找答案,而不是给出一套严格的算法去计算出答案。 论文作者一共发现了5个可识别的“启发式规则”类型,包括: ● Range Heuristic (范围启发式) 当计算数或结果落在特定数值范围内时激活。 ● Modulo Heuristic (取模启发式) 当数值满足特定的模运算条件时激活。(就像刚才提到的50模余[5,25]) ● Pattern Heuristic (模式启发式) 当数值匹配特定的数字模式时激活。(比如百位有1,十位有2) ● Identical Operands Heuristic (相同数启发式) 当运算符号左右数量一致的时候激活。(比如44-44,结果就是0) ● Multi-result Heuristic (多结果启发式) 能同时加权多个不相关结果出现的概率,多出现在除法运算中(比如3,5,9的概率都增大) 实际上这五个种类的“启发式”可以被简单理解成两种模式。 一种是通过之前的训练直接预测结果,可以说是“直接启发式”,但它不是给定结果,而是给一个范围。这一方面可能是训练数据本身不足以给出直接结果,另一个是直接给出结果的模式在数据上容易形成过拟合。 另一种则是找到一些对于结果的规律,间接去猜测结果数的属性。这可以被称为“间接启发式”。它是用之前的训练去预测结果可能具有的一些数学属性,比如模式启发式、取模启发式都是这种。 但无论哪种,都还是一种模式识别,而非对真正运算规则的掌握。 作者在这个过程中测试了一共四种模型,最大的是Llama3-70B。虽然这个模型确实展现出了最复杂和成熟的启发式规则系统,但其依然仅仅是启发式的。因位这就是由自回归模型的本质决定的。 至此,现阶段基于Transfomer架构的自回归模型学不会逻辑推理和规则这件事,基本上可以下个结论了。 这一倾向其实不光在语言模型和算术领域出现,在字节最新的一篇论文中,他们测试了图像生成模型是否能理解物理规律,结果依然是否定的。 他们发现,模型采用的仍然是“基于案例”的学习方式,而非抽象物理规则,并且其理解的优先级也非常倾向于表征特征,而非规律特征。是以颜色 > 尺寸 > 速度 > 形状排列的。 最后,他们对模型进行了Scaling Up,拓展了其大小,结果表明单纯扩展规模并不能实现模型对基础物理规则的发现。 其本质根源也许正是在于自回归模型的自身限制。 所以,也许杨立昆说的是对的? 比如说一道数学题,通过COT可以把它拆解成一步步的简单步骤。这样就可以把一个复杂的运算拆成数个简单的运算,一步步进行下去了。如此,大语言模型就能完成比较复杂的数学计算,如四则运算了。 它的训练也非常简单,就是在后训练阶段加入人工合成的示例集微调,其中对于每个问题, 训练数据包含: 1. 问题描述 2. 中间推导步骤 3. 最终答案 这相当于降低了之前论文提到的子群的复杂性,这样里面解题的每个步骤都在Transfomer模型本身的模式识别范围内。 从论文给出的例子中,比如在处理3x+3y+12z=6这个公式时,模型会先对所有数都除以3,得到x+1y+4z=2,再将它与其他多项式相减。它对步骤的拆解非常接近我们“按照数学计算规则”的做题流程了。 作者还尝试了长度外推(length extrapolation)实验,去测试模型的这种步骤拆解是否有泛化能力。他发现,即使仅有3层的Transformer架构模型,在长达18个数的运算序列上仍然保持了相当高的准确率(虽然有所下降)。而在训练之中用到的数据最多只有15个数之间的运算。这说明模型并不是单纯记忆,而是学会了其中的某些规律,并组合这些规律去求解更难的问题了。 作者由此乐观的判断说,模型通过COT是真正的学会了数学规则。只要在训练过程中给出的多项式长度足够丰富,Transformer+COT这个组合应该可以理解所有的数学规则。 但是否真是如此呢? 就论文给出的证据来看,我们完全可以将COT训练过程,理解为模型学习识别和模仿特定的"问题拆解模式"。在训练数据中,模型接触到大量按照特定格式展示的分步计算过程,从而学会了如何将复杂计算分解成一系列简单步骤。 然而,这种模式识别能力与真正理解数学计算规则是有本质区别的。如果一个模型真正掌握了数学运算规则,它应该能够处理任何符合这些规则的计算,而不受训练数据模式的限制。虽然实验显示模型能够处理比训练数据更长的算式,表现出了一定的泛化能力,但随着长度增加准确率逐渐下降的现象,恰恰说明模型更可能是在进行模式匹配和应用,而非真正理解了数学运算的本质规则。 另一篇由COT论文作者,先OpenAI研究员姚顺雨参与的论文也显示:即使是当下最先进的经COT加持的模型OpenAI-o1,也还是逃不过自回归模型所表现出的概率偏好。OpenAI-o1能让大模型
学会真正的逻辑吗?
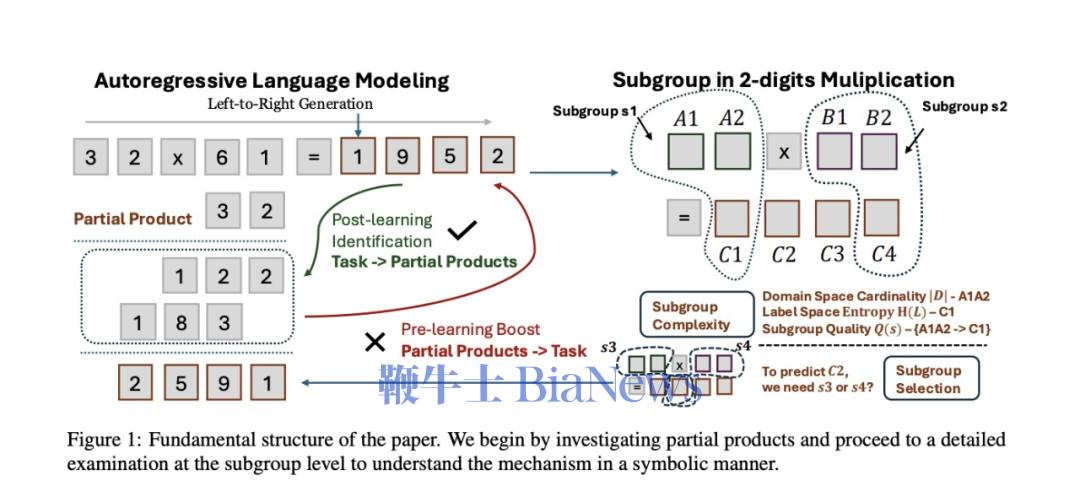






在针对四个任务的实验中,虽然o1-preview的波动表现比起其他模型要小,但依然训练数据越多,输出概率越高时,模型的表现越好。
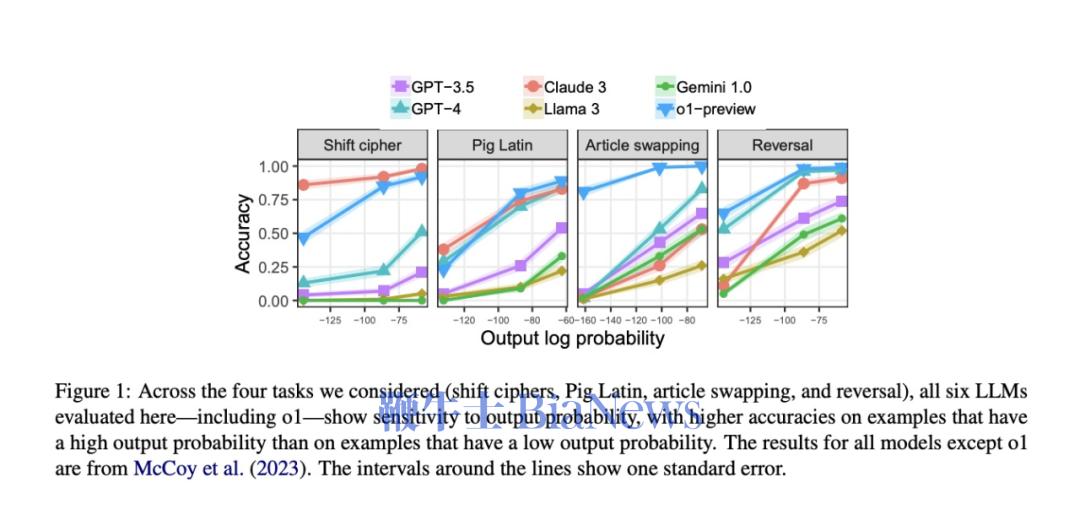
(横轴表示输出的对数概率,数值越大(越接近0)输出概率越高。纵轴表示准确率) 但无论如何,在COT的加持之下,模型确实在思维模式上更接近我们人类推理的“形式”,能用我们熟悉的方法做数学了。 但这条路能否真正通向对于规律的理解,至少当下还不明确。
 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握



