

Key Points
DeepSeek单周下载量高达约240万次,可能超过豆包在前一年春节期间通过广告投放达到的下载量;
引发美股大跌的是两个模型DeepSeek-V3和DeepSeek-R1,前者是类4o模型,后者是类o1模型;
DeepSeek-V3训练成本只有Llama 3的1%,DeepSeek-R1推理成本只有OpenAI o1的3%;
DeepSeek-V3的大量创新都与克服使用H800(而不是H100)所带来的内存和带宽不足有关;
R1系列模型放弃了RLHF的HF(人类反馈)部分,只留下纯粹的RL(强化学习),这个过程中模型涌现了「反思」能力;
DeepSeek还用其80万条思维链数据微调了阿里的Qwen模型,结果后者的推理能力也提升了;
DeepSeek尚未推出金融投资大模型,不过这只是时间问题。
1月27日一早,DeepSeek在中国区和美国区苹果App Store免费榜上同时冲到了下载量第一,超过原先霸榜的ChatGPT,这也是国产应用首次实现这一成就。而半个月前(1月11日),DeepSeek的App才刚刚上线iOS和安卓的应用市场。
当天晚些时候,DeepSeek应用程序开始出现宕机。公司称其服务受到了大规模恶意攻击,因此将暂时限制新用户注册。当晚开盘的美国科技股则集体大跌——费城半导体指数(SOX)下跌9.2%,创下2020年3月以来的最大跌幅。其中英伟达股价下跌近17%,市值蒸发近6000亿美元,规模创美股史上最大。此外,博通、台积电、ASML、Google和微软也分别跌了17.4%、13%、7%、4%和2.14%。就连WTI原油盘中也一度下挫3%,因为有交易员认为,如果大模型的训练和推理不再需要那么多算力,那么数据中心的电力需求也会减少,自然也不需要那么多石油来发电。
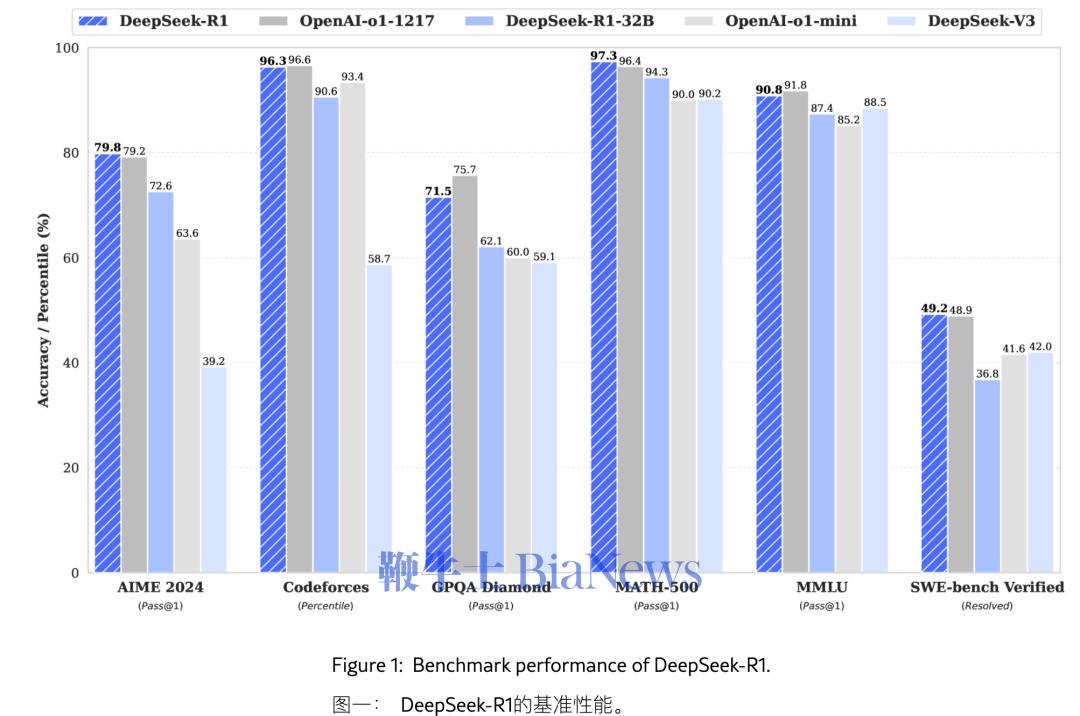
DeepSeek称DeepSeek-R1模型在各项能力上追平OpenAI o1。
DeepSeek是一家位于杭州的大模型公司,2023年才创立。2024年年中之前,这家公司并没有引起市场多少关注。但2024年最后一个月,它密集发布了多个模型。其中圣诞节后发布的名为DeepSeek-V3(以下简称「V3」)的模型,宣称在性能上「相当于」业界领先的闭源模型GPT-4o与Claude-3.5-Sonnet,「优于」最好的开源模型Meta的Llama 3,且总训练成本仅为557.6万美元,这个数字只有(据估计投资超过5亿美元)前者的1%;临近2025年农历春节的1月20日,它又发布了一个名为DeepSeek-R1(以下简称「R1」)的模型,同样的,DeepSeek在论文中声称R1模型「在一系列任务上实现了与OpenAI o1相当的性能」。
1月29日,彭博社引述要求不具名的知情人士报道,称微软的安全研究人员在2024年秋季发现DeepSeek的员工使用OpenAI的API窃取了大量数据,言下之意是这些数据可能被用来训练V3或R1模型。然而OpenAI明确规定不允许其他公司使用其模型生成的数据训练模型,2023年年中,字节跳动就曾因类似行为与OpenAI发生摩擦。目前DeepSeek暂未对此言论发表回复。
麻烦不止于此,同日意大利当局要求 DeepSeek 提供有关该公司如何处理用户数据的信息,DeepSeek将有20天时间来准备答复,目前DeepSeek已从意大利地区苹果和Google的应用商店下架了应用。
外界对于DeepSeek仍存在大量质疑,比如其模型是否只是美国先进模型的蒸馏模型、其创新是否真的重要,以及美国科技股是否反应过度。这些问题DeepSeek其实在技术报告中基本都回答了。
1. DeepSeek引起的全球技术圈恐慌是如何形成的?
1月27日的市场震荡比DeepSeek在模型论文中发表的惊人数据晚了差不多一个月。直到一周前的2025达沃斯论坛上,虽然已有不少人谈起DeepSeek,但意见也多为保守或充满质疑的。比如DeepMind首席执行官Demis Hassabis就在达沃斯声称,DeepSeek的模型的确有些「出人意料」,但他表示「对DeepSeek模型的工作原理并不确定,包括它在多大程度上依赖其他美国公司模型的结果」。
在这种怀疑「V3是个蒸馏模型——蒸馏了美国的前沿模型」的观点之外,另外一种不愿相信DeepSeek成果的声音代表来自Scale AI的首席执行官Alexandr Wang。他在接受CNBC采访时声称,DeepSeek拥有5万块英伟达最先进的AI芯片H100,言下之意是DeepSeek违反了美国的芯片禁运政策,才取得了模型突破。由于芯片管制,2022年秋季起,英伟达就不再向中国市场提供其最高端的AI芯片H100,取而代之的产品是内存和带宽都更受限的H800——性能仅为H100的一半。
然而与此同时,Meta员工在匿名网站称,DeepSeek仅用1%的投入就实现了超越Llama 3的性能这件事,已经使公司AI团队陷入恐慌,特别是考虑到公司正在训练的下一代模型Llama 4的预期投入比Llama 3还要贵好几倍。技术媒体The Information紧接着报道称,Meta成立了4个专门研究小组来研究DeepSeek的工作原理,并基于此来改进Llama。在V3发布之前,Llama是全球能力最强的开源模型,直到V3发布后取而代之。
如果只有V3的效率,DeepSeek可能并不能引起足够注意。1月20日发布的R1模型为DeepSeek的热度添了重要的一把火——这是一个类o1的推理模型,并且即刻就能在应用程序中体验到。与ChatGPT等其他聊天机器人的不同之处在于,DeepSeek的同名聊天机器人在回应用户提问时,会将思维链条(Chain of Thought,CoT)完全展示出来,其作为机器人认真揣摩用户需求、试图将用户所有说出口或隐晦表达的情绪都安慰到位的「内心活动」激发了大量用户的热情。商业的本质在于创造稀缺,无论在人类成员还是AI成员中,共情能力都是稀缺品。

DeepSeek在自言自语时更有「人味」。
CoT是类o1模型都在发展的一项能力,人类差不多也是如此进行推理的。然而这类思考过程同时也是各人工智能公司想要保密的重要数据资产。如果你在ChatGPT中询问它的o1模型是如何思考的,几次之后,OpenAI可能就会发邮件给你警告要撤销你的账号了。
风险投资机构Andreessen Horowitz (a16z)的创始人安德森(Marc Andreessen)对R1的描述是「人工智能的Sputnik时刻」,Sputnik是苏联于1957年首次发射的人造卫星。另外一些人则称DeepSeek这一系列模型的发布是美国AI界的「珍珠港事件」。意思是作为全球人工智能领域的技术高地,美国正在失去自己所建构的AI商业模式和技术护城河。
2. DeepSeek-V3到底取得了怎样的突破?
DeepSeek的突破来自于两个层面:低成本和推理能力。其中,V3的突破主要在于训练成本和计算效率,R1开辟了训练推理模型的新路径。
具体来说,V3的采用了优于传统MoE(专家模型)架构的DeepSeekMoE架构,以及优于传统多头注意力(MHA)的DeepSeekMLA(多头潜在注意力)。
DeepSeekMoE(Mixture of Experts,混合专家)
传统稠密模型,比如GPT-3.5,在训练和推理过程中激活全部参数。然而事实上,并非模型的每个部分都是当前任务所必需的。因此,MoE的理念是将模型区分为多个「专家」,推理时只激活对任务必要的专家。GPT-4也是一个MoE模型,据说有超过1.67万亿个参数,其中大部分参数分布在16个专家模块(如FFN层)中,每次完成特定任务时,大约一到两个专家会被激活,所以大大降低了计算量。DeepSeek的V3拥有6710亿参数,其中活跃专家中的参数总和为370亿。
DeepSeek在V3模型论文中称,相较于传统MoE,DeepSeekMoE使用了「更细粒度」的专家,使专家更加专门化,单个专家仅数十亿参数,提升了任务适配性;同时,DeepSeekMoE将一些专家隔离为「共享专家」,用于减轻专家之间的知识冗余,从而使V3模型在激活相同数量专家和参数的情况下表现更好。
DeepSeekMLA(Multi-Head Latent Attention,多头潜在注意力)
多头注意力(Multi-Head Attention,MHA)是生成式AI计算的核心机制,它让模型可以同时关注用户输入的不同层面,并行处理这些不同维度的信息,再将其整合起来完成响应。。这一并行处理过程与图像处理中的并行计算类似,因此过去用于图形处理的GPU(Graphics Processing Unit)成了AI计算的理想硬件平台。
不过这一过程同时会产生大量缓存,限制了推理效率。DeepSeekMLA找到了一种对其中的缓存数据进行联合压缩的方法,从而大大减少推理期间的内存使用,保证高效推理。DeepSeek在论文中称,得益于这些创新,其V2模型(V3模型的上一代)在单节点搭载8块H800 GPU的情况下,实现了超过每秒5万个token的生成吞吐量,是上一代模型最大生成吞吐量的5.76倍。
MTP(Multi-Token Prediction,多tokens预测)
传统大模型回答用户需求时只预测下一个token,V3通过MTP技术同时预测下2个token。这里的关键是第二个预测token的准确性问题(即「接受率」,预测的token能被最终采用的比例)。DeepSeek评估称,在不同生成主题中,其模型所生成的第二个token的接受率达到了85%至90%。这种高接受率意味着V3能够以接近传统单token预测模式两倍的速度来生成文本。
FP8:低精度训练
FP8的意思是8位浮点(floating-point),数字越高,意味着计算精度越高,但与此同时计算速度会降低。DeepSeek使用了FP8数据格式来训练V3,并在模型计算的不同环节实现了数据在FP8、BF16、FP32等不同精度下的灵活和交替使用,即一种混合精度框架。在参数通信的部分过程,DeepSeek也做到了FP8精度的传输。通过这一过程,DeepSeek实现了加速训练和减少GPU内存使用,并「首次在超大规模模型上验证了FP8混合精度训练框架的有效性」。
DeepSeekMoE + DeepSeekMLA架构早在DeepSeek开发V2模型时期就已开拓,V2模型验证了这一组合可以在保持性能的前提下兼顾高效训练与推理,V3不过是在此基础上进行了多项改进。真正使得V3模型在能力上超越Llama 3的,是另一项创新——自我奖励。
后训练(post-training):自我奖励
在进行了不到两个月的预训练、花费了266.4万个GPU小时后,DeepSeek又用0.5万个GPU小时对V3进行了一种以「自我奖励」和蒸馏为主的后训练。
强化学习的典型案例是AlphaGo,通过为模型提供围棋规则,并告诉它怎样算是赢得比赛,然后模型就会自己找到满足这一切目标的路径。不过这种机器学习方式中的最大难题是如何设置奖励函数,数学、编程、围棋等推理能力要求高的领域通常具有明确的答案,边界分明,然而除此之外的其他生活领域却未必如此。OpenAI的o1模型发布之后,外界充满了对其究竟对强化学习过程设置奖励函数的好奇。OpenAI不再open后,DeepSeek在其论文中表明了它是如何给V3模型设置奖励函数的——直接将V3模型自身作为奖励生成模型,自己决定是否奖励自己。
DeepSeek将V3的判断能力与GPT-4 o和Claude-3.5的判断能力进行了比较,称V3的性能与GPT-4o-0806和Claude-3.5-Sonnet-1022的最佳版本相当,并且,V3的判断能力还可以通过投票技术来增强。因此,DeepSeek将V3的评价和多次投票结果作为「奖励函数」,为开放式问题提供自我奖励。
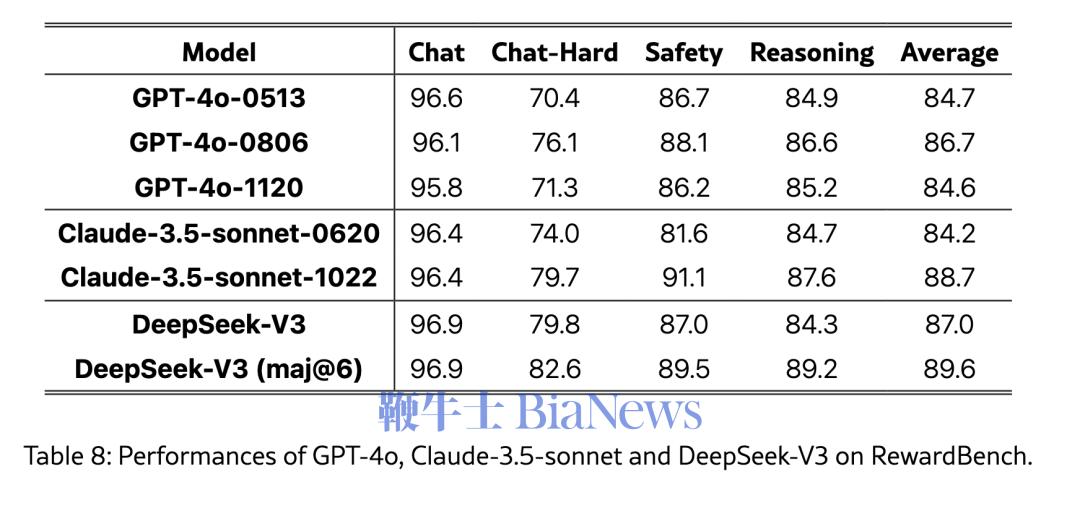
DeepSeek认为,有判断能力的基础模型本身就是足够好的奖励模型。
「LLM(大语言模型)本身就是一款多功能处理器,能够将来自不同场景的非结构化信息转化为奖励,最终促进LLMs的自我完善。」DeepSeek在发表V3模型的论文中称,意思是如果一个大模型足够优秀、有判断力,那么它应该像优秀的人类一样,足够用来对AI的回答作出评价。这一过程是V3模型超越Llama 3的关键。
3. 为什么DeepSeek做到了这种低成本,其他厂商尤其美国厂商没有做到?
「资源的诅咒」一词用在这个时候再合适不过了。相较于中国厂商,美国大模型公司们都有多得多的现金和算力为其大模型开发开路,英伟达也在不断推出算力更强大同时也更昂贵的芯片满足这些大厂的需要。大模型的Scaling Law(缩放定律)早就从模型本身向上延伸至了资金环节。不少大模型厂商——不止国内,都因预训练的昂贵在去年下半年退出游戏。
对那些资源丰富的大厂而言,阻力最小的方法是大肆招聘、支付高薪以及向英伟达支付高昂费用。而DeepSeek-V系列的几乎所有创新都与适应带宽受限的H800芯片有关。
4. DeepSeek-V3是个蒸馏模型吗?
V3的训练成本公布之后,外界对它的最大质疑就是它可能是个从其他先进模型那里蒸馏出来的模型。
在V3、R1模型的相关论文中,DeepSeek的确都在结尾强调了在蒸馏技术上的探索。比如在V3模型中,DeepSeek就使用了从DeepSeek-R1系列模型中提取的推理能力——R1作为教师模型生成了80万训练样本进行训练。「从DeepSeek R1系列模型中提取推理CoT(思维链),并将其纳入标准LLMs(大语言模型),特别是DeepSeek-V3。我们的流水线将R1的验证和反思模式优雅地整合到了DeepSeek-V3中,显着提高了其推理性能。」DeepSeek在论文中称。
除了将从R1系列模型中提取的80万思维链样本用以训练V3,DeepSeek还进一步探索了将这些数据应用于阿里巴巴旗下的Qwen2.5系列模型后的效果。DeepSeek在论文中称,经过这种后训练的Qwen系列模型(DeepSeek-R1-Distill-Qwen-7B和DeepSeek-R1-Distill-Qwen-32B)效果「明显优于之前的版本,并与o1-mini相当」。「我们证明了较大模型的推理模式可以被提取到较小的模型中」,DeepSeek称,这为大模型的「后训练」优化提供了一个有希望的新方向。
不过,这些尝试并不意味着DeepSeek的低成本模型V3本身是个蒸馏模型。根据其论文中的说法,V3的上一代模型V2使用了8.1万亿个token数据训练,V3模型的预训练数据扩展到了14.8万亿。论文显示,V3总共使用了约280万GPU小时(包括266.4万小时预训练、11.9万小时上下文长度训练和0.5万小时后训练),完成了约39.7亿亿次浮点运算。这个计算量与训练14.8万亿token的数据集的理论需求相符。也就是说,按照DeepSeek的DeepSeekMoE+DeepSeekMLA架构、用FP8的低精度训练和传输数据、一次预测多个token,DeepSeek的确可以做到不到600万美元的成本。这是个合理数字。
5. 相较于DeepSeek-V3,DeepSeek-R1进步在哪里?
V3模型和R1系列模型都是基于V3模型的更基础版本V3-Base开发的。相较于V3(类4o)模型,R1(类o1)系列模型进行了更多自我评估、自我奖励式的强化学习作为后训练。
在R1之前,业界大模型普遍依赖于RLHF(基于人类反馈的强化学习),这一强化学习模式使用了大量由人类撰写的高质量问答以了解「什么才是好的答案」,帮助模型在奖励不明确的情况下知道如何作困难的选择。正是这项技术的使用使得GPT-3进化成了更通人性的GPT-3.5,制造了2022年年底ChatGPT上线时的惊喜体验。不过,GPT的不再进步也意味着这一模式已经到达瓶颈。
R1系列模型放弃了RLHF中的HF(human feedback,人类反馈)部分,只留下纯粹的RL(强化学习)。在其首代版本R1-Zero中,DeepSeek相当激进地启动了如下强化学习过程:为模型设置两个奖励函数,一个用于奖励「结果正确」的答案(使用外部工具验证答案的最终正确性),另一个奖励「思考过程正确」的答案(通过一个小型验证模型评估推理步骤的逻辑连贯性);鼓励模型一次尝试几个不同的答案,然后根据两个奖励函数对它们进行评分。
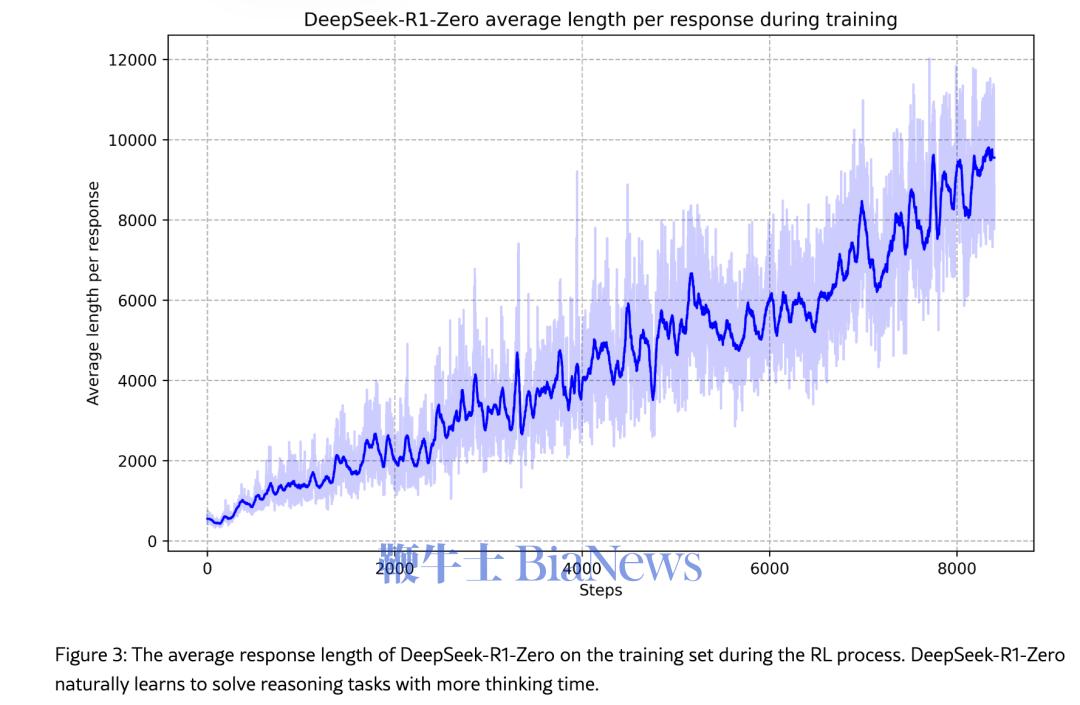
DeepSeek称,R系列模型在强化学习中涌现出了「反思」能力。
DeepSeek发现,由此进入强化学习过程的R1-Zero生成的答案可读性较差,语言也常常中英混合,但随着训练时间增加,R1-Zero能不断「自我进化」,开始出现诸如「反思」这样的复杂行为,并探索解决问题的替代方法。这些行为都未曾被明确编程。
DeepSeek称,这种「啊哈时刻」出现在模型训练的中间阶段。在此阶段,DeepSeek-R1-Zero通过重新评估其初始方法来学习分配更多的思考时间。「这一刻彰显了强化学习的力量和美妙——只要提供正确的激励,模型会自主开发高级解决问题的策略。」DeepSeek称,经过数千个这样的「纯强化学习」步骤,DeepSeek-R1-Zero在推理基准测试中的性能就与OpenAI-o1-0912的性能相匹配了。
DeepSeek在论文中说,「这是第一个验证LLMs的推理能力可以纯粹通过RL(强化学习)来激励,而不需要SFT(supervised fine-tuning,基于监督的微调)的开放研究。」
不过,由于纯强化学习训练中模型过度聚焦答案正确性,忽视了语言流畅性等基础能力,导致生成文本中英混杂。为此DeepSeek又新增了冷启动阶段——用数千条链式思考(CoT)数据先微调V3-Base模型,这些数据包含规范的语言表达和多步推理示例,使模型初步掌握逻辑连贯的生成能力;再启动强化学习流程,生成了大约60万个推理相关的样本和大约20万个与推理无关的样本,将这80万个样本数据再次用于微调V3-Base后,就得到了R1——前面提到,DeepSeek还用这80万个以思维链为主的数据微调了阿里巴巴的Qwen系列开源模型,结果表明其推理能力也提升了。
6. DeepSeek彻底解决推理问题了吗?是否意味着AGI不需要新范式?
DeepSeek在V3模型上的创新都是工程上的,其突破的更大意义在于改变大模型的既有商业模式以及美国对华的芯片制裁——V3的大量创新都与为克服使用H800而不是H100所带来的内存带宽不足有关。为此,DeepSeek甚至绕过了英伟达的编程工具CUDA,对每块H800芯片上132个处理单元中的20个进行了重新编程,以专门用于管理跨芯片通信。
相较而言,R1在纯强化学习上的探索至少达到了与OpenAI o1相当的水平,o1背后的技术是否与R1相同的问题目前未知,OpenAI没有公开过其o1模型的强化学习方案。不同大模型公司在强化学习中设置奖励函数的方式从来都千差万别。
不过,还不能说R1彻底解决了推理问题,至少只要基于o1的代操作AI——Operator还不能像人一样自如操作各种电子设备,就不能说这种水平的AI就是通用人工智能了。目前,Operator理论上可以根据用户要求执行鼠标和键盘允许的所有操作:只要用户口头交代一下,它就可以帮用户订外卖或查找旅游路线;遇到问题或者操作出错时,它能利用强化学习带来的推理能力自我纠错;实在无法解决问题时,它会将控制权交还给用户——就像自动驾驶一样,AI遇到无法决策的困境时会将方向盘交还给人类司机。也和自动驾驶一样,这种「接管率」将是观察基于强化学习的AI是否在进步的指标之一。
7. DeepSeek的成果会如何影响AI产业的未来?
美国科技股1月27日的表现已经初步表明了DeepSeek接连发布的几个模型对市场的影响力大小和范围。
DeepSeek的低成本模型发布之际,美国总统特朗普刚刚宣布一个总额达5000亿美元的AI基础设施项目,OpenAI、软银等都已承诺参与其中。稍早前,微软已经表示2025年将在AI基础设施上投入800亿美元,Meta的扎克伯格则计划在2025年为其人工智能战略投资600亿至650亿美元。DeepSeek的低成本模型使人们开始怀疑这些规模惊人的投资是否是种浪费,如果只用数百万美元,而不是数亿元,就能训练一个4o等级的模型,那大模型对于GPU芯片的需求可能只是当下的1/10甚至1/100。
英伟达的股价因此跌得最厉害,不过长远看,受冲击最大的不一定是英伟达,而会是其他自研大模型并根据模型调用建立商业模式的公司,OpenAI、Anthropic、月之暗面、字节跳动等都属于这一范围。推理成本上,OpenAI o1每百万输入和百万输出token分别收取15美元和60美元,而DeepSeek R1同样输入与输出的价格分别只要0.55美元和2.19美元,差不多只是前者的3%。此前,OpenAI向使用其最先进模型o1的用户收取每月200美元的订阅费,而且仍然处于亏损状态并打算提价,DeepSeek R1的出现可能令ChatGPT的提价计划泡汤。
此外,一大批中国大模型公司比如字节跳动和月之暗面2024年花在用户增长上的广告费可能会打水漂。数据监测公司Sensor Tower的数据显示,自今年1月11日上线以来,DeepSeek App的累计下载量已超过300万次,其中,80%的下载量集中在1月20日至1月26日的一周内。如果保持这种增速,DeepSeek不久就会进入有千万用户的AI应用阵营。
股价大跌近17%后,英伟达在一份声明中称,DeepSeek的成果证明了市场对英伟达芯片的需求会更多(而不是更少)。这一说法有一定道理,因为当模型训练和推理都变得更便宜、只需要消耗更少算力,人工智能的商业化可以进展更快,比如,R1的小型版本能够在普通家庭电脑上运行,这将有助于推动AI应用的普及与民主化——像苹果这样为大模型提供终端设备的公司会是赢家。1月27日的美国科技股大跌中,苹果也是仅有的两家没有下跌的技术公司,另一家是拥有云计算业务的亚马逊,它同样在自研大模型上落后,但拥有无论什么模型都需要的云计算生意。
相较于训练环节,进入商业化后的推理环节会消耗更多倍的算力。而且,更有效的使用计算的方法并不意味着更多的算力没有用。不过短期内,向英伟达大手笔下单的技术公司们会变得更谨慎。
当然,最大的赢家还是消费者。
8. 为什么幻方——一家量化投资公司——要大力投资人工智能?
DeepSeek由梁文峰于2023年12月创立,在此之前,他于2015年成立了名为「幻方量化」(High-Flyer)的量化对冲基金,该基金通过AI分析金融数据从而作出交易决策。2019 年,幻方量化成为国内首个募资超过1000亿元的的量化对冲基金。
虽然一直有声音认为金融市场就像变幻莫测的天气一样无法预测,这些人可能正确,但1980年代以来,不断有数学家和计算机科学家希望为价格建模,并据此赚到钱。1988年至2018年的30年间,美国量化投资巨头文艺复兴科技创造了39.1%的年化复合收益率,远超过巴菲特、索罗斯等传统靠人来决定何时下注的投资大师。
这些量化基金并不追求预测金融市场下一刻的价格,而是专注于寻找发现市场中存在特定的价格模式。比如「24小时效应」模式:周一的价格变化常常是周五趋势的延续,而这个趋势到了周二就会反转(24小时效应);「周末效应」:如果市场在周五展现出清晰的上升趋势,那么周五收盘前买入再到下周一一早卖出,也大概率会赚钱;再比如有的资产一旦第一天升值了,它第二天大概率会继续升值,反之亦然。这些有预测能力的金融信号就此成为量化基金们用以指导投资的交易因子(indicators),虽然潜在盈利空间没那么大,只要交易频率够高(与价值投资倡导的刚好相反),量化基金们就能吃到市场的肥尾。
大模型擅长从大规模数据中寻找模式,这种能力正对热衷从金融数据中寻找交易因子的量化基金的胃口。幻方量化也不例外。DeepSeek目前尚未推出相应的金融投资大模型,不过这只是时间问题。(转载自:新皮层NewNewThing)
 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握



