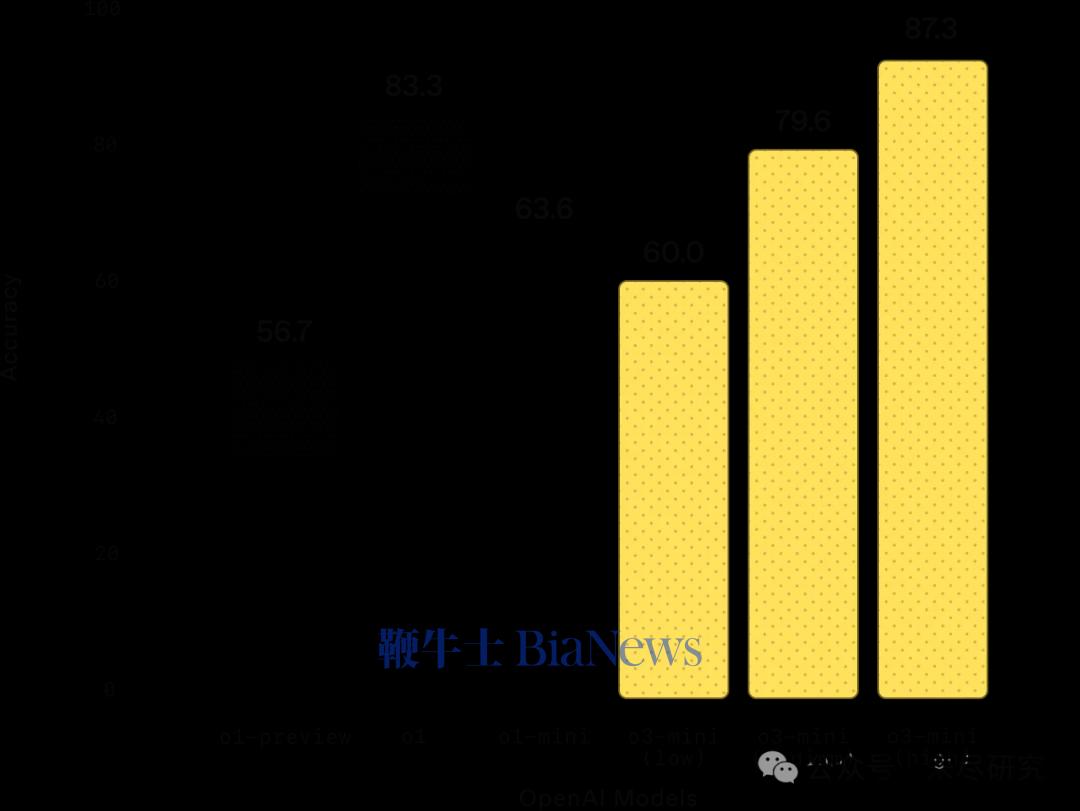
OpenAI全力反扑了,也在开源这件事上开始反思了。在1月最后一天,OpenAI发布了免费版的o3 mini,技术报告显示它的低配版超过了o1 mini,中高配版本的各项基准测试,基本上都超过了o1。OpenAI踩着它在去年底定下的Deadline如期发布,并没有完全反映出已经改变了的AI竞争游戏规则。o3 mini的价格相比o1 mini下降了63%,比o1下降了93%,但总体性价比仍然没有超过DeepSeek R1。AI的竞争,已经不完全是性能的竞争,尤其是在性能领先收窄时,真正的竞争是成本-智能前沿边界之争,即关于性价比平价的竞争。从这一点上来说,以DeepSeek为代表的中国开源模型,再如阿里巴巴刚刚发布的Qwen 2.5 Max,目前显得积极主动,它们鼓励自己被用于广泛蒸馏,迅速扩大生态。可能已经意识到了这一点,OpenAI CEO奥特曼承认:在开放模型权重这一问题上,我们站在了历史错误的一边。这次o3 mini推出了3个版本,low、medium和high。其中用于快速高级推理的low和擅长编程和逻辑的high版本已经上线,所有ChatGPT用户都可使用,付费的plus用户使用次数扩大至原先的三倍至每天150次。o3-mini的性能得到显著提升。我们先"照本宣科"一下它的基准测试分数:
数学:在低推理强度下,OpenAI o3-mini 的表现与 OpenAI o1-mini 相当;在中等推理强度下,o3-mini 的表现与 OpenAI o1 相当。而在高推理强度下,o3-mini 的表现优于 OpenAI o1-mini 和 OpenAI o1。灰色阴影区域表示基于 64 个样本的多数投票(共识)性能。(来源:OpenAI)
--
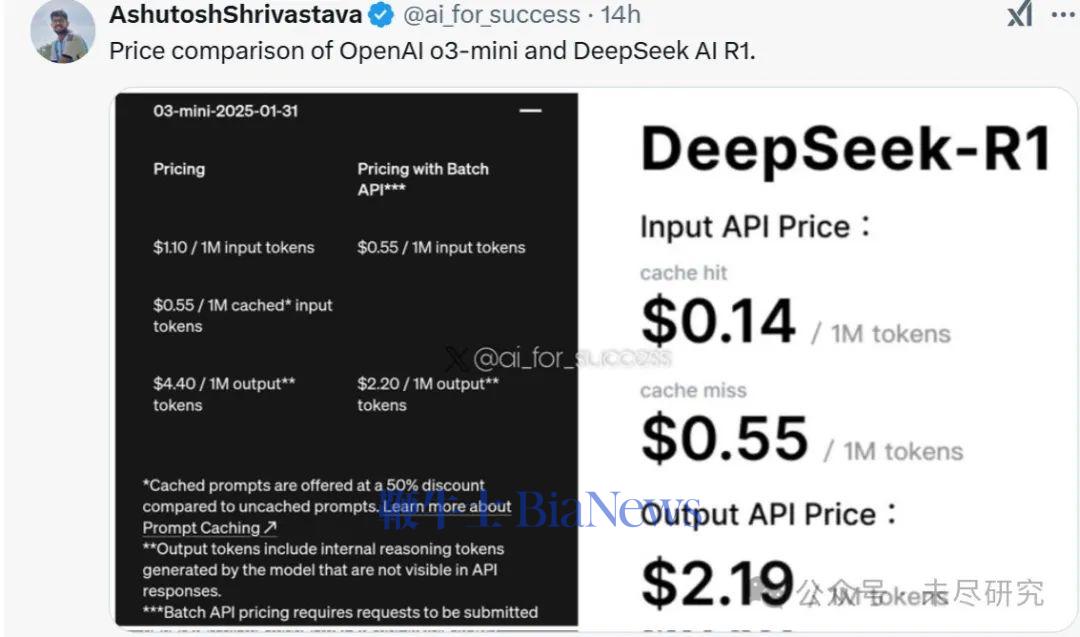
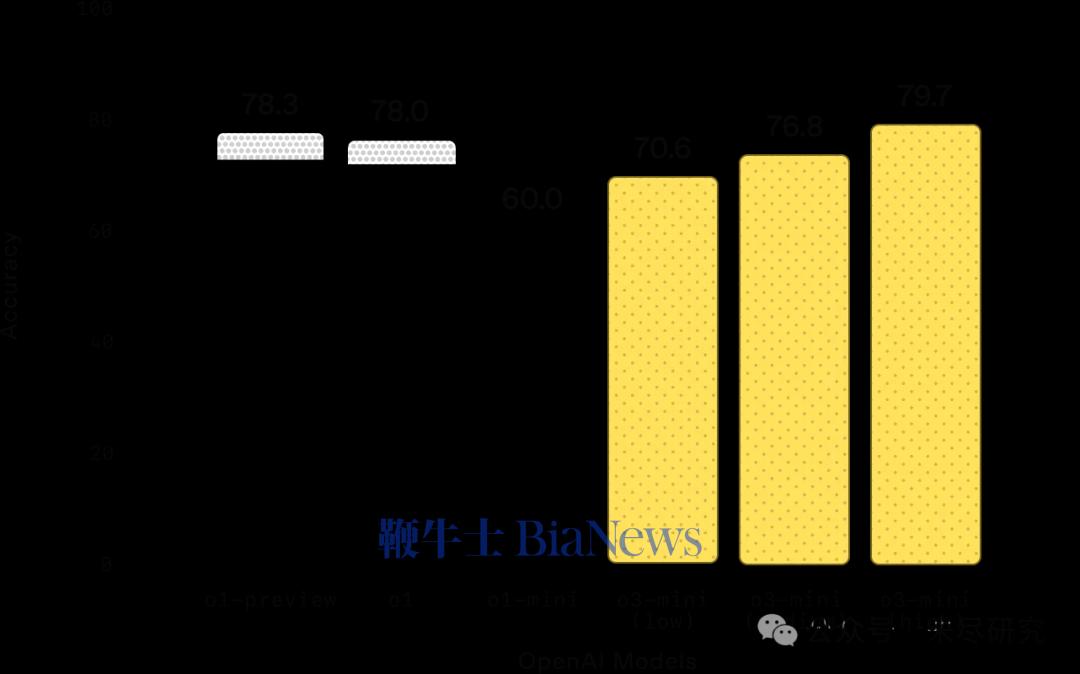
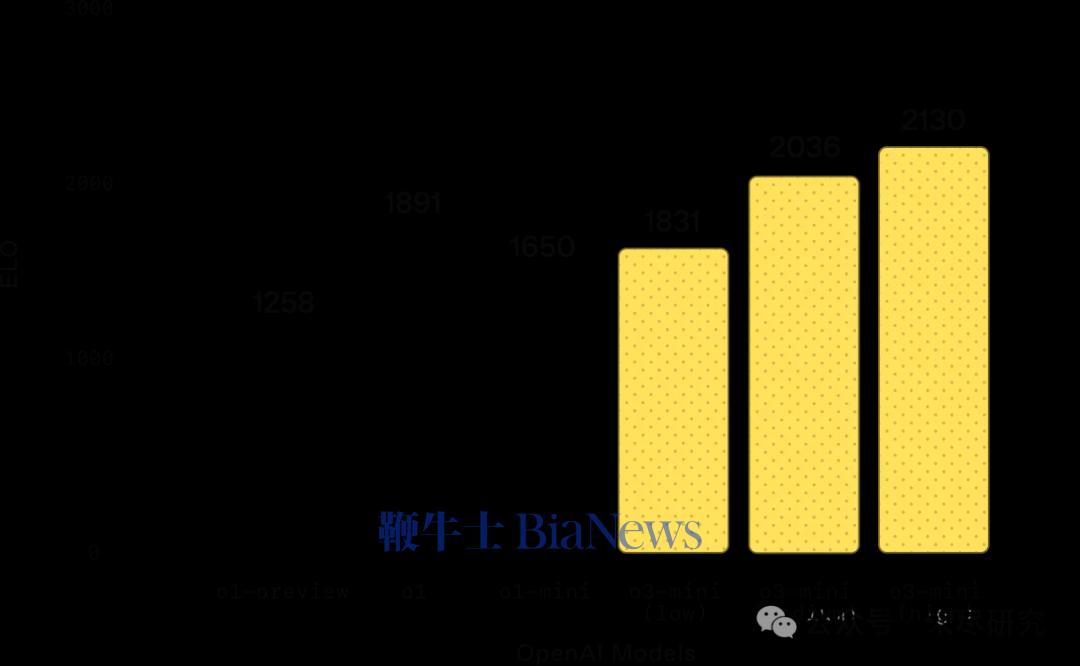
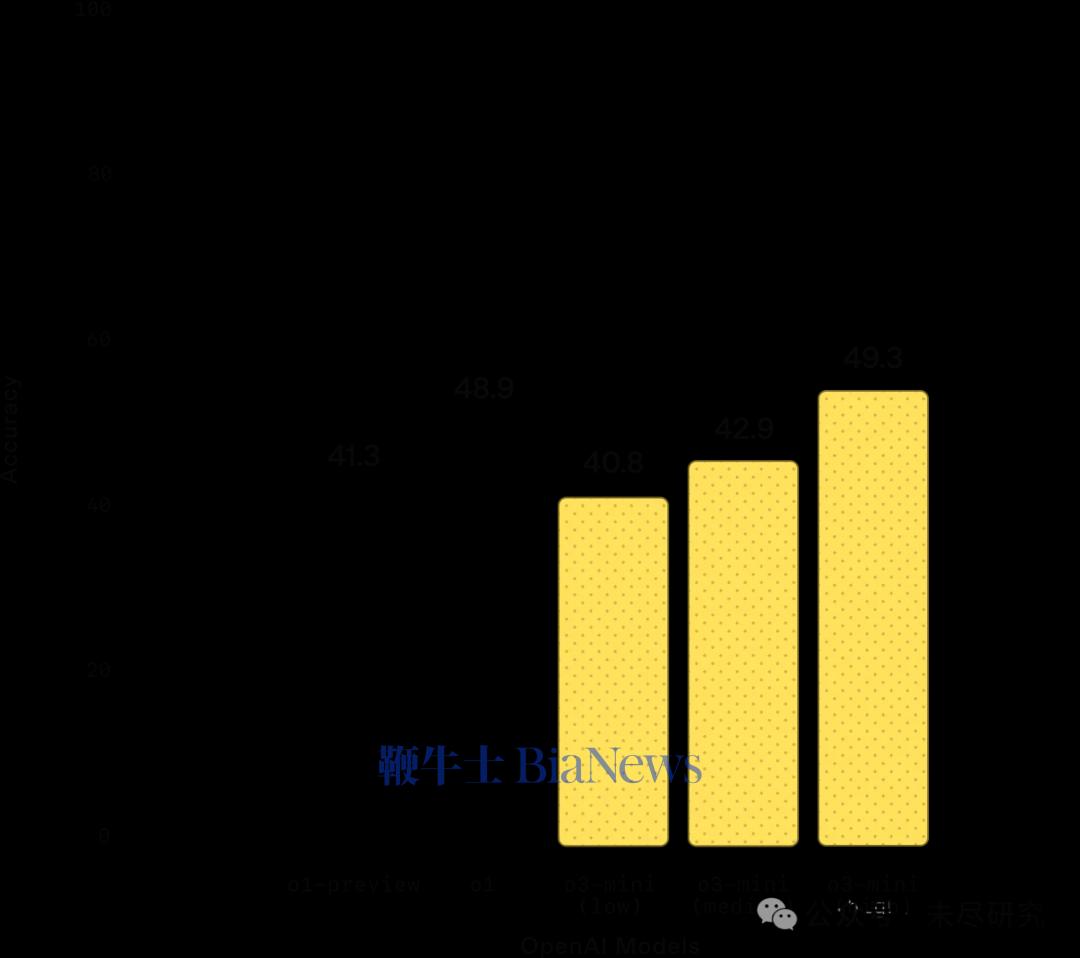
博士级科学:在博士级生物、化学和物理问题上,OpenAI o3-mini 在低推理强度下的表现优于 OpenAI o1-mini。在高推理强度下,o3-mini 的表现与 OpenAI o1 相当。(来源:OpenAI )研究级数学:在 FrontierMath 测试中,OpenAI o3-mini 在高推理强度下的表现优于其前代模型。当被提示使用 Python 工具时,o3-mini 在高推理强度下能在首次尝试中解答超过 32% 的问题,其中包括超过 28% 的高难度(T3)问题。这些数据为初步结果,上方图表展示的是未使用工具或计算器的表现。竞赛编程:在 Codeforces 竞赛编程测试中,OpenAI o3-mini 随着推理强度的增加,其 Elo 评分逐步提升,并在所有推理强度下均优于 OpenAI o1-mini。在中等推理强度下,o3-mini 的表现与 OpenAI o1 相当。(来源:OpenAI )软件工程:在 SWEbench-verified 测试中,o3-mini 是我们迄今发布的表现最优模型。关于 SWEbench-verified 在高推理强度下的更多数据点,包括使用开源的 Agentless scaffold(39%)和内部工具 scaffold(61%)的结果。(来源:OpenAI)延迟:o3-mini 的首个 token 生成时间比 o1-mini 平均快 2500 毫秒。(来源:OpenAI )OpenAI称,o3-mini 的发布,标志着 OpenAI 在推动“高性价比智能边界”上的又一重要进展。“自 GPT-4 推出以来,每 token 价格已降低 95%——同时依然保持顶级推理能力。随着人工智能应用的加速普及,我们将继续站在前沿,打造兼具智能、效率与安全性的大规模 AI 模型。”OpenAI的强化学习科学家Noam Brown认为,o3 mini移动了推理模型的价格曲线。但许多分析人士认为,这还不足以匹配 DeepSeek R1/v3 的价格曲线,它比o1降价25倍之多。DeepSeek已经把AI的竞争带入了性价比之战,而不再是由几家闭源大模型凭借先发及资源优势,掌握着定价权。早在2023年初,开源模型Llama的发布,曾经引起一阵“羊驼家族”小模型的热潮,这些从Llama中蒸馏出来的小模型,在一些性能上不输于基础大模型,而且能精简到装入PC和手机。当时谷歌内部已经有人发出警告,我们没有护城河,OpenAI也没有。2024年5月,当DeepSeek V2发起一场价格战时,硅谷一些人已经敏锐地感到一股“来自东方的神秘力量”开始出现,但并没有引起太多的关注。直到DeepSeek在一个月内接连发布V3 和R1,才以美国AI巨头暴跌万亿美元的惨剧,宣告美国前沿闭源大模型对AI定价权的崩溃,进入了中美两极竞争的时代。硅谷AI创业者和投资人Shawn Wang,根据技术报告估算了o1-o3系列的成本-性能边界曲线。从这张图可以看出,DeepSeek总体上仍处于更前沿的成本-智能边界,目前的未知数是刚发布的Gemini 2.0 Flash Thinking,它还没有公布服务的价格。
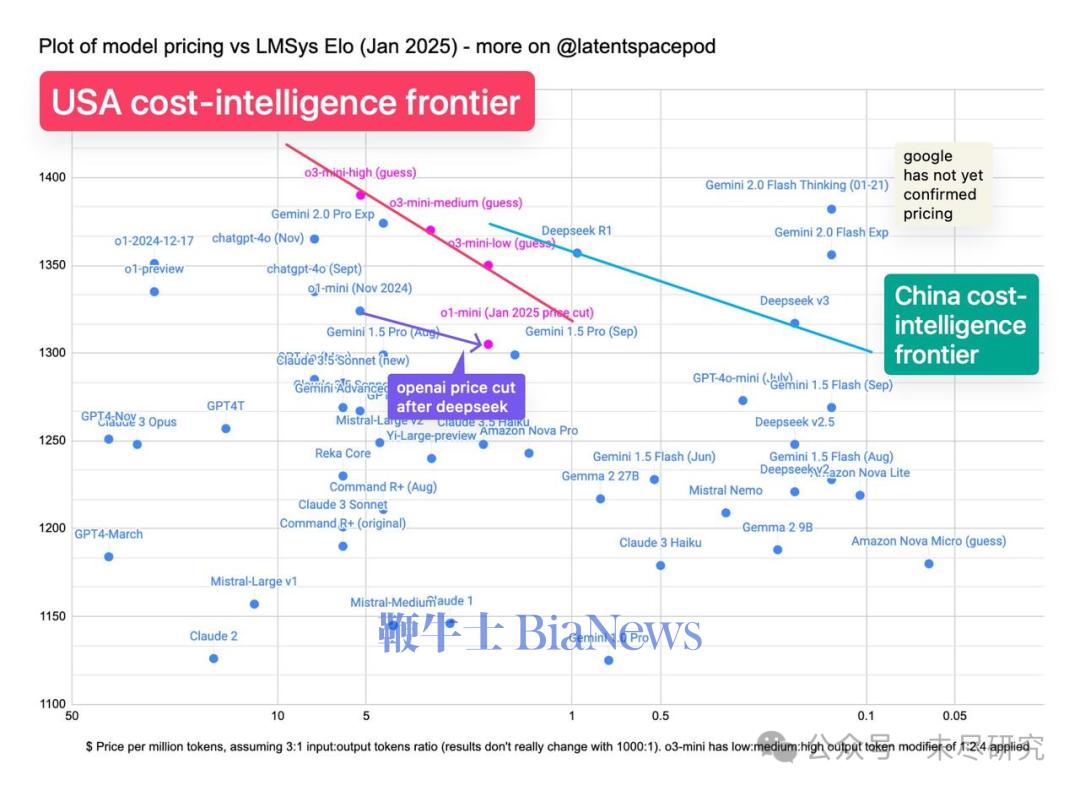
(来源:latent.space )
当下有实力在成本-智能的前沿边界上竞争的,是OpenAI,Gemini,DeepSeek三家,如果中国再加上一家的话,应该是阿里的Qwen。至于说到Claude,它有可能在这场竞争中沦为二流,难怪其创始人阿莫迪发表了一篇万字长文,力主美国对中国加强GPU禁运,因为一旦在十万到百万级GPU基础上的生态竞争,目前价格最贵的Claude将难以招架。奥特曼在Reddit上已经承认,即使OpenAI继续开发出更好的模型,但已经不会如以前几年那样领先了。他将考虑OpenAI的开源,如把一些旧的模型开放,但这目前并不是OpenAI的优先事项。OpenAI正在全力以3000亿美元的估值融资400亿美元,同时在推进5000亿美元的星际之门数据中心基础设施计划。而DeepSeek正在激活中国从芯片到应用的AI生态,硅基流动和华为云联合首发并上线基于华为云昇腾云服务的DeepSeekR1/V3推理服务。中国相对于美国较薄弱的基础模型、芯片和数据中心,正在形成合力。既然OpenAI出手了,Grok-3 和Gemini Pro还坐得住吗?下周可能更精彩。DeepSeek V3炸裂了他们的圣诞新年和12连发,他们也要一窝蜂地炸裂我们的春节,直到十五。(转载自:未尽研究)




 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握



