

DeepSeek 今年春节火遍中国之后,腾讯是第一个全线产品尽数接入的巨头,从微信、QQ 到腾讯自己的 AI 助手元宝和才上线几个月的工作台产品 ima。这被认为是腾讯 AI 投入爆发的开始。
但据我们了解,改变比这早几个月。从去年下半年起,微信便探索起了 AI 相关的能力。DeepSeek 出来以前,腾讯高层也已着手,将分散在各事业群里的工具产品打包起来,统一管理。
腾讯最新公布的财务数据也证实了这一点。腾讯在 2024 年最后三个月将该季度大部分税后经营所得——390 亿元——用于资本开支,主要是采购显卡、投建算力中心。这意味着腾讯一个季度的 AI 基建投入接近此前两年的总和。
ChatGPT 在 2022 年底上线。隔年 2 月,GPT-4 模型推动中国科技行业全面投入 AI。但这之后近两年,腾讯不论投资还是产品都显得不太着急。
这是腾讯投入节奏的改变。
此前十来年,每当行业巨变、对手逼近,腾讯会调动力量快速应战,通常第一批产品都不能改变局面,却总能留在牌桌上,再来一次,最后打出绝杀。
比如短视频。从外部看,微视是一款失败的产品——砸钱砸流量做大一款不够好的产品,但随即快速陨落。但客观说,微视作为腾讯的短视频反击也实现了一定战略价值——试错、为后续产品争取时间,也储备了人才。今天,视频号的日活跃用户数超过 5 亿,逼近抖音主应用,是明确的行业第二。
游戏战场从 PC 转手机,腾讯是这样过来的,移动支付、音乐也有类似的经历。
当 AI 大模型成为新的技术变革,腾讯大致延续了类似的应对,但下场节奏完全变了。
2023 年初,ChatGPT 问世几个月后的一次管理层战略会上,腾讯技术与工程事业群总裁卢山以 ChatGPT 举例,认为 OpenAI 从推出 GPT 模型开始,“花了三年时间才真正产品化,而腾讯的大模型肯定会很多坑要踩,所以不会着急。” 一位在场人士转述他的话。腾讯的 AI 助手产品元宝在 2024 年 5 月底才发布,比豆包、Kimi 晚了近一年。
当阿里与字节在大模型、软件和硬件上全面出击时,一位腾讯人士记得,腾讯董事局主席兼 CEO 马化腾跟一些 AI 团队说,“要好好与外部合作,不要想着什么都自己做”。2024 年,字节在为豆包大举投放、成为英伟达重要客户时,腾讯则花费了 1120 亿港元回购股份,创下了其年度回购金额的历史新高。
“在等待一个拐点。” 上述腾讯人士说,“Pony(马化腾)对内说的是,要清醒地认识到实际情况,不要过高估计自己的能力。” 腾讯要抓的是 AI 应用的机会,但过去两年里出现的国产大模型,能力都远不足以支撑一个好的 AI 应用。
“微信的网络效应牢不可破,他们只要耐心等待底层的新技术成熟,再加以善用就可以了。” 一位字节跳动 AI 业务的负责人说。
大力投入发生在 2024 年的最后一个季度。当时阿里已经广泛投资了一批创业公司;字节则孵化出了数十款 AI 产品,旗下豆包也成为了中国用户数最多的 AI 助手类产品,“对手的激进也让腾讯有了紧迫感。” 一位腾讯人士说。回头看这是坚定的投入,也是绝佳的运气。
几个月后,基金公司幻方默默投入四年孵化的开源大模型 DeepSeek 出人意料地点亮了中国的 ChatGPT 时刻,为整个行业重新画了一条起跑线。
腾讯和阿里最新一季的资本开支都超过了 2023 全年。 意外之喜,DeepSeek 重画了一条起跑线 2025 年初,腾讯的高层们在一次总办会上决定,将原本分散在各部门的 AI 应用打包起来,放到一个事业群里集中管理,让技术与工程事业群(TEG)专注于大模型的技术研发。不过究竟由哪个事业群来管理,并无定论。 在经历了几年的降本增效后,腾讯绝大部分业务部门都已盈利,进入相对稳定的状态。“尽管 AI 代表了未来,但也意味着高度的不确定性。” 上述腾讯人士说。 最终,云与智慧产业事业群(CSIG)主动把这个任务接了下来,原本隶属于技术与工程事业群(TEG)的 AI 助手产品腾讯元宝,以及隶属于平台与内容事业群(PCG)的 QQ 浏览器、搜狗输入法、ima 等工具产品都将陆续迁至 CSIG。 这是腾讯 AI 战略的第一次转变。过去两年,腾讯在 AI 业务上的布局从未呈激进之态。进入 2025 年,大模型能力的进一步提升让智能体(Agent)与 AI 应用的落地成为可能,腾讯决定可以先动起来了,“而且 AI 这种大机会不应该赛马,得集中资源押注。” 上一年,字节跳动不仅研发大模型,还推出了数十款软硬件产品;一位字节人士透露,公司原本要给抖许多业务拿来打仗的预算也被部分调剂给了 AI 业务;新的一年,字节还将斥百亿美元储备芯片。 1 月 20 日,来自深度求索的 DeepSeek-R1 模型横空出世,腾讯的姿态在此刻彻底扭转。DeepSeek-R1 是国内唯一一个性能比肩 OpenAI o1 并达到应用级程度的大模型,最重要的是它完全开源,还在极短时间里拥有了国民级的品牌辨识度。 腾讯没有一丝犹豫,所有业务接入 DeepSeek-R1。“老板们的态度非常明确:先走出来看看再说,否则永远不知道接下来会怎么样。” 一位腾讯人士说。 不少业务部门在春节期间加起了班。腾讯云最早上线了 DeepSeek-R1 及 V3 原版模型 API 接口;其次是 AI 智能工作台产品 ima 与 AI 助手元宝。2 月 16 日,微信搜一搜灰度测试接入了 DeepSeek。 这显然是一次计划之外的 “练兵”。一位接近腾讯的人士透露,微信灰度测试接入 DeepSeek 后流量突然激增导致算力告急,集团紧急调度自有数据中心资源,但仅能调拨出有限的服务器机架。 不得已,微信只能控制灰度测试的数量,并将更多用户分流至腾讯元宝上。由于元宝的流量是逐步累加的,节奏可控,腾讯也有更多时间来准备算力。 几乎同一时间,腾讯开始下单买卡补充算力,保证 DeepSeek 能在腾讯系的产品内平稳运行。春节后,“寒武纪也拿到了几百片来自腾讯的测试订单。” 一位知情人士说。 相比之下,字节跳动对于旗下产品是否接入 DeepSeek 反而犹豫了。“内部一开始的普遍想法是,反正 DeepSeek 就在那儿,什么时候接都行,不急。” 一位字节 AI 产品经理说。一个春节过后,“很多产品突然意识到迟了,于是匆忙组织团队紧急加班开发,接入 DeepSeek。” 不过目前,抖音、豆包等核心产品仍坚持使用字节的自研模型。 今年 2 月底,腾讯元宝在接入 DeepSeek 后,开启了激进推广,投放力度超过了豆包和月之暗面的 Kimi,还一度越过 DeepSeek 冲上了 iOS 免费榜的第一名。根据 QuestMobile 数据,元宝的日活跃用户数只用了一周时间便增长了十倍,逼近 260 万。 一位接近元宝人士说,这款产品在去年定下过一个日活跃用户数超百万的目标,但实际上并没有投入太多资源买量,“核心策略是借势腾讯内部的产品和应用。” 比如曾与腾讯视频一同开发 AI 角色陪聊的功能;也曾在《王者荣耀》周年庆之际,与项目组探讨开发游戏内的数字互动形象。 DeepSeek 激活了腾讯久违的战斗力。上述元宝人士称,现在这个阶段谈卡位、占入口都太早了,但 DeepSeek 的出现确实给了腾讯一个机会,能让业务借此找找做 AI 产品的手感、感受市场的水温,“否则如果后面真的机会来了后,我们连怎么做都不知道。” 大模型,从 AI Lab 的边缘尝试变成腾讯高层每天讨论的议题 腾讯是较早开始研究 AI 的中国互联网公司,2016 年成立的 AI Lab 则是推动腾讯 AI 研发与产业应用的核心部门之一。 早年间,AI Lab 从百度研究院、IBM 沃森研究中心、微软研究院等机构招揽来了一批科学家助阵。原雅虎研究院主任科学家、百度研究院副院长张潼便曾担任 AI Lab 的创始主任。第二年,腾讯总裁刘炽平在一次财报会上提到,人工智能具有战略意义,腾讯会对 AI 进行持续、长期而有耐心的投资。 AI Lab 有着国内大公司少见的宽松、开放的研究环境。它的的员工不用背负硬性考核指标,他们曾以在顶级会议上发表的论文数作为绩效标准,但很快便发现这个目标太容易实现了。 一位知情人士回忆,AI Lab 曾在一年时间里投中了 20 篇 ACL(国际计算语言学协会年会)论文,刷新了国内纪录,“后来内部慢慢就不怎么提这个目标了,还是想做影响力更大些的事情。” 各团队研究的方向也无需与集团业务强绑定,于是许多人探索起了 AI 医疗、机器人,还有一些几乎找不到落地场景的方向,“只要你认为是正确的,基本也能做下去。” 上述人士说。生成式大语言模型便是其中之一。 在 ChatGPT 问世前,学界与业界普遍将基于双向注意力机制的预训练范式(如 Google BERT)视为技术演进主流,但腾讯 AI Lab 仍保持了在生成式大语言模型上的研究。 团队也不用太考虑研究的投入成本——2020 年,他们用上了数十亿量级的参数训练模型,比 OpenAI 在前一年推出的 GPT-2 要大几倍。相比之下,当时国内多数研究团队受算力与资金限制,只用得起几千万量级的参数训练。 只是一段时间过后,AI Lab 团队发现大模型的表现总不尽如人意,还有严重的幻觉问题。当时 GPT-3 的发布也没有增添太多信心。于是一些参与者开始朝更垂直的落地场景继续探索,更多人则将精力转移到了更务实的搜索、广告、推荐技术上去了。 戏剧性的一幕发生在年底,ChatGPT 问世并在全球掀起风暴,这款产品史无前例地上线仅两个月便揽入了上亿用户,甚至被认为将彻底重构传统互联网的业务形态。“有太多的没想到。” 一位参与大模型研发的腾讯人士说,“以前从没想过做千亿级参数的生成式模型训练,也想不到能直接给模型纯文本指令来做监督微调。” 一位腾讯人士说,从 2023 年起,马化腾开始每周和各业务部门的技术专家们开会讨论大模型,“许多会还是一对一的。” 腾讯高层间建了一个针对大模型技术变革的分享和讨论群。5 月的腾讯股东大会上,马化腾直言,“我们最开始以为(人工智能)是互联网十年不遇的机会,但是越想越觉得,这是几百年不遇的。” 技术部门也被集结了起来。腾讯 AI Lab 因长期研究自然语言处理,冲在了最前线,旗下的美国西雅图实验室负责训练起了新的大模型。不过因为这个团队常年埋头钻研学术,缺少项目开发与管理的经验,最终做出的大模型效果欠佳。 恰在此时,与 AI Lab 同属技术与工程事业群(TEG)的机器学习平台部和数据平台部也训练了一个大模型,这支团队有丰富的业务落地经验,在这场竞速中胜出。 一位腾讯投资部人士称,ChatGPT 出来后,腾讯曾讨论过,是否要激进投资国内的大模型创业公司。“刚开始是挺着急的”,所以最初的策略是尽可能每家都投一点。但随着研究的深入,腾讯的判断发生了转变:训练大模型对算力要求非常高,不是一般创业公司能玩得起的游戏,与其花高价激进投资,不如把钱留下来,做好自己的模型。“心一下就定了下来。” 腾讯 TEG 也很快组织起了一支联合战队,机器学习平台部负责大模型基座与纯文本的模块、数据平台部负责多模态模块、安全平台部负责预训练数据等,所有工作流程、管线开始从零开始搭建与磨合。腾讯其它的事业群也派出了自己的技术负责人支援。 与多数大公司一样,腾讯最初在训练大模型时也付出了不少的探索成本。 最早显现出来的是芯片能力的问题。DeepSeek 是先花了大量时间和资源,解决好了这类最底层的硬件问题,最后才在模型训练时效率飙升。但几个大公司都在同时追逐每个新的技术热点,一位腾讯人士说,“目标太多了,只能边开飞机边修引擎,优化效果效率很难像他们那么高。” 新组织的磨合也需要时间。起初,文本团队与多模态团队的协作不够紧密,导致前者未能及时调整文本模型进行端到端训练,最终只能采用低效的两阶段模式(先单独训练各模块再整合)。 在训练视频模型时,新团队得先花大半年的时间,将每日处理的视频数据量级从上百万提高到千万以上。相比之下,在一些公司,大模型是由业务相关的团队操刀训练的,他们原本每天就在处理几千万的视频素材,类似的工程环节便不再需要重新摸索。 “不过一旦把底层的架构和组织梳理清楚,效率就能明显提升,这也是我们过去两年主要在做的事情。” 一位知情人士说。进入 2025 年,混元大模型的节奏明显也在加快,上线业界首个一站式 3D 内容 AI 创作平台—混元 3D AI 创作引擎、推出了混合 Transformer-Mamba MoE 架构的混元的混元 Turbo S,又在 3 月发布并开源其图生视频模型、推出了基于 Turbo S 基座模型的深度推理模型 T1,以及 5 个 Hunyuan 3D-2.0 系列的 3D 生成模型。 “公司在积极拥抱 DeepSeek 的同时,并没有任何减少对混元的投入。” 上述腾讯人士说。他认为即便从防御的角度,腾讯也一定不会放弃自己的模型。 有稳固的壁垒,但也有更迫切的挑战 当美国科技巨头重注押宝大模型时,苹果成了一个孤本。它自己没有激进研发最先进的大模型,而是选择与 OpenAI 等公司合作,将对方的 AI 能力接入自己的平台。尽管 Apple Intelligence 严重延期,但苹果的股价并没有因此暴跌。 苹果投资者的共识是,随着 AI 普及,人们将需要便捷的用户入口、更强的本地运算能力,只要 AI 颠覆不了智能手机,苹果就是这场技术变革的受益者。 腾讯有着类似的独特位置。它有最便捷的入口:微信是中国人使用最多的手机应用,用户数超过了 13 亿。目前 AI 产品偏向对话的用户界面,和这个入口天然契合。中国的第二大对话入口则是 QQ。它们是最能让 AI 迅速普及到所有人的渠道。 “内部提的一个词叫 AI 普惠,即借助自己的产品能力和规模优势,更多人使用上 AI。” 一位腾讯人士说。 腾讯的另一个独特优势源于用户信任与合规的数据生态。AI 服务若想真正贴近需求,就需在严格隐私框架下,更理解一个人。一位微信人士称,作为国民级社交平台,始终将隐私保护置于技术演进首位。 2025 年,马化腾鼓励所有业务部门都去大胆尝试 AI 转型。他承诺每个团队都能有充足的卡来训练模型,也不再要求业务与腾讯自己的混元大模型强绑定,“外部如果有更合适的基座模型就用外部的。” 一位腾讯人士说。 马化腾关注每一个创新产品,无论体量大小。年初,他就曾提议,是不是可以把 ima(由 QQ 浏览器孵化的一款智能工作台产品)镶嵌进 QQ 浏览器。 据我们了解,微信和 QQ 团队目前正在重点探索 AI 相关的功能。 前景无限开阔,但迫近的问题非常现实,腾讯需要大兴 AI 基建。 字节跳动传统业务高度依赖推荐算法,在几年前便是中国 GPU 算力规模最大的公司。它的 AI 基建投资也先于对手启动。 腾讯去年底开始的大规模资本开支要变成算力需要相当长的时间。 买卡是第一个问题。全球的先进制程芯片制造商都在 24 小时生产,但进口的 GPU 和国产 GPU 产能总和也不能满足中国各大巨头今年的需求。 更麻烦的是 GPU 需要放进专门设计的算力中心。一般而言,建一座算力中心需要 9-12 个月的时间,投建还受到持牌承包商产能、城市电力规划等多方面的限制,缺口比买卡更严重。 一位深入研究 AI 的二级市场人士测算,目前的主流 AI 产品如果服务 1 亿日活用户,需要约 40 万张卡的算力,这大约对应十个新的算力中心。而微信全球月活 13 亿,大部分在中国。 这个计算还没有考虑新的 Agent 产品,如果类似 Manus 的产品开始流行,单个用户每天需要的算力可能还会再翻几倍。 刘炽平在 2024 年报后的营收会上也提到了算力紧缺的问题。“我们必须把这些 GPU 装到数据中心里,这需要一些时间。所以我们在今年一季度没能抓到那么多需求。” 这一轮的 AI 竞争,DeepSeek 很大程度上拉平了大厂之间的模型差距,让 AI 应用的尝试和普及成为可能,这利好腾讯。但要抓住可能到来的新需求,每个大公司都得准备好足够庞大的算力,这是需要钱才能解决的问题,但并不是光有钱就能很快解决。(转载自晚点LatePost)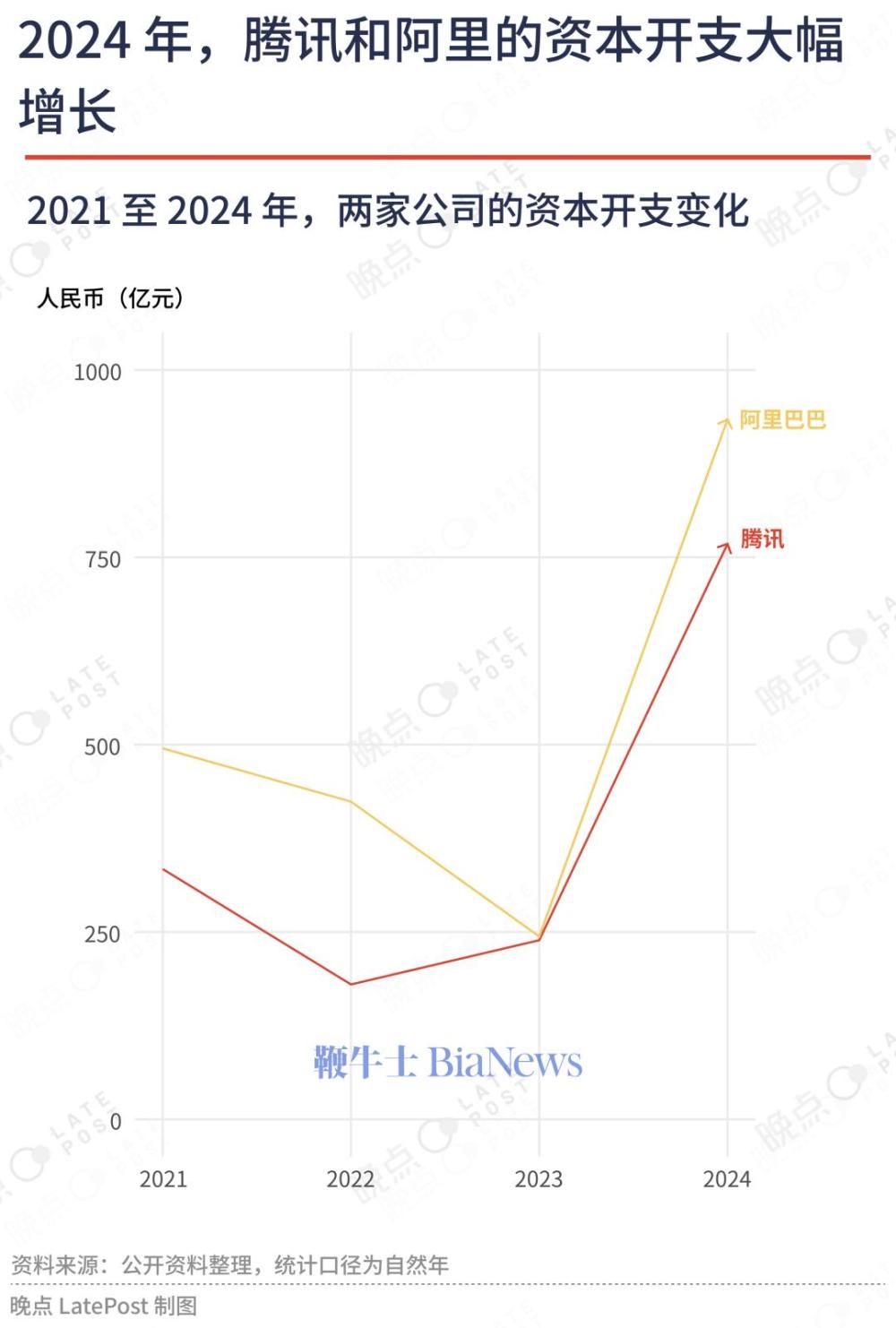
 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握



