

随着多模态大模型在人工智能领域的广泛应用,其安全性问题日益受到关注。近日,复旦大学联合香港城市大学、新加坡管理大学的研究团队在视觉-语言模型安全防御领域取得重要进展,提出了一种基于强化微调的黑盒防御新架构——BlueSuffix,为解决多模态大模型在实际应用中的安全性和可靠性问题提供了创新性解决方案。论文已被ICLR 2025接收。

近年来,将多模态能力融入大语言模型(LLM)的研究显著增加,但多模态融合在提升模型能力的同时,也带来了跨模态鲁棒性问题,尤其是跨模态越狱攻击的威胁日益凸显。现有防御方法主要分为白盒和黑盒两类:白盒防御虽能直接访问模型参数,但存在应用场景受限、算力需求高等问题;黑盒防御虽不依赖模型内部结构,但现有方法未能充分利用跨模态信息,且对良性样本的回复效果影响较大。
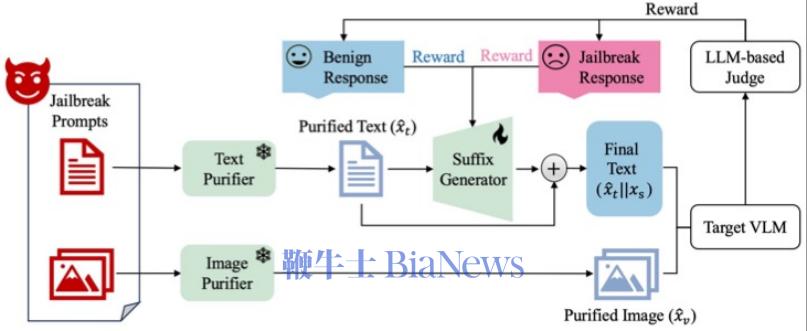
研究团队提出的BlueSuffix架构创新性地结合了图像和文本防御技术,通过双模态协同防御机制提升模型安全性(如图1所示)。该架构首先利用视觉和文本净化器进行初步防御,随后通过强化微调技术优化语言模型(GPT-2)生成蓝队后缀,显著提升了模型对跨模态越狱攻击的防御能力。实验表明,BlueSuffix在保持良性样本性能的同时,有效降低了跨模态攻击成功率。 图1:BlueSuffix防御示例 BlueSuffix由三部分组成(如图2所示):1)基于扩散模型的图像净化器,用于防御视觉输入中的对抗性扰动;2)基于大语言模型的文本净化器,按照特定模板重写文本提示,在不改变原意的前提下使视觉-语言模型更容易识别输入文本提示存在的有害内容;3)基于大语言模型的蓝队后缀生成器,通过强化学习,融入视觉和文本信息对轻量的语言模型(GPT-2)进行微调,以应对跨模态鲁棒性问题。引入图像净化器和文本净化器既可以帮助后缀生成器做进一步防御,又可以降低后缀生成器生成后缀时对良性样本回复效果的负面影响。 图2:BlueSuffix框架图 (1)基础防御性能 研究团队在4个主流视觉-语言模型(LLaVA、MiniGPT-4、InstructionBLIP和Gemini)和4个基准数据集(AdvBench、MM-SafetyBench、RedTeam-2K和Harmful_Instruction)上对BlueSuffix进行了系统性评估,验证了其在防御效果、模型迁移性和鲁棒性方面的优越性能。 实验针对6种典型攻击方法(VAA、imgJP、GCG、AutoDAN、Vanilla Attack和BAP Attack)进行了防御测试,并与6种基线防御方法(DiffPure、Safety Prompt、Diffpure+ Safety Prompt、R2D2、CAT和VLGuard)进行了对比。结果表明,BlueSuffix在攻击成功率(ASR)和Perspective API评分两项关键指标上均表现出显著优势(如图3所示)。 特别值得注意的是,BlueSuffix对VAA、imgJP、GCG和AutoDAN四种攻击的防御成功率达到了100%(ASR=0),即使面对当前最先进的跨模态攻击BAP Attack,其防御效果也远超现有方法(如图3所示)。 (2)通用性验证 为进一步验证BlueSuffix的通用性,研究团队在RedTeam-2K数据集上进行了迁移性实验,如图4所示。结果显示,BlueSuffix在开源和商业视觉-语言模型上均表现出优异的迁移能力,分别将BAP Attack的攻击成功率降低了约70%和50%(如图4所示)。这一结果证明了该方法的广泛适用性。 (3)鲁棒性测试 此外,研究团队还引入了自适应攻击场景,通过动态调整攻击策略验证BlueSuffix的鲁棒性。实验结果表明,即使在对抗性环境下,BlueSuffix仍能保持稳定的防御性能,展现了其在实际应用中的可靠性。 图3:BlueSuffix的防御性能结果 图4:BlueSuffix的通用性验证结果 本研究的主要贡献可概括为以下两个方面: (1)创新性防御架构 研究团队提出了基于强化微调的黑盒防御新架构BlueSuffix。该架构采用模块化设计,各组件具有即插即用特性,能够灵活整合现有图像与文本模态的防御方法,为多模态大模型安全防御提供了通用解决方案。 (2)基于强化学习微调的跨模态优化 BlueSuffix创新性地提出了基于强化微调的跨模态优化方法。该方法通过结合文本与视觉模态信息,将轻量级语言模型微调为蓝队后缀生成器,在保持模型原有对齐性能的同时,显著降低了对良性样本回复效果的影响。这一突破性方法为多模态大模型的安全防御开辟了新方向。(转载自AI科技评论)


 扫码下载app 最新资讯实时掌握
扫码下载app 最新资讯实时掌握



